La L3 cache multibanco en AMD Bulldozer.
Poco a poco se acerca la comercialización de los procesadores basados en la nueva micro arquitectura de AMD prevista para el 7 de junio. Actualización: finalmente llegará al mercado en Septiembre según los últimos roadmaps.
Conforme pasan los días se va filtrando nueva información sobre su estructura interna y también algunos datos acerca de su rendimiento, o por lo menos del rendimiento de algunos Engineering Samples.
En este artículo hablaré sobre la estructura de la caché L3 en Bulldozer y sobre su funcionamiento.
La caché L3 multibanco: 4 x 2 MB
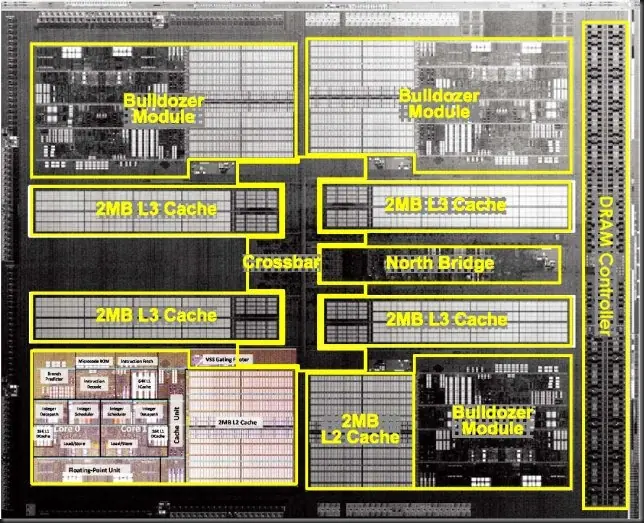
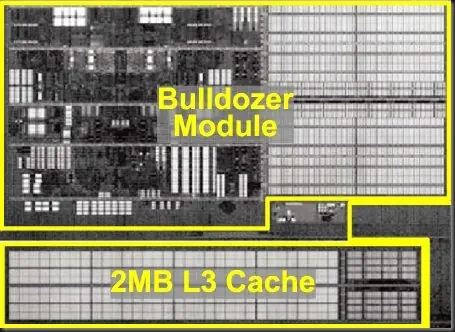
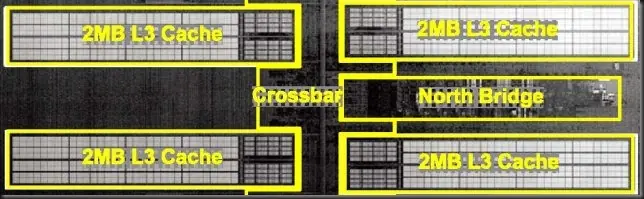
AMD ha diseñado una caché L3 particionada en 4 sub arrays de 2 MB y 16 vías cada uno. la capacidad total en el chip de 4 módulos y 8 INT cores es de 8 MB y 64 vías de asociatividad.
El diseño es exclusivo, la L3 no incluye los datos presentes en la L2 de 2 MB de cada módulo y en cambio es una Victim Cache, donde se alojan las páginas desalojadas desde L2.
Con una frecuencia estimada en 2.4 GHz los anchos de banda son los siguientes:
307.2 GB/s en lectura gracias a sus dos accesos por ciclo de 128 bit y por módulo.
2 400 000 ciclos/s x 4 módulos x (2 accesos/ciclo x 128 bit) = 2 457 600 000 bit / 8bits/1 byte = 307 200 000 bytes/s = 307.2 GB/s
153.6 GB/s en escritura gracias al acceso de 128 bit por ciclo.
2 400 000 ciclos/s x 4 módulos x 128 bit = 1 228 800 000 bit / 8bits/1 byte =152 600 000 bytes/s = 153.6 GB/s
Por lo que se desprende de este documento, la caché L3 está conectada con cada módulo Bulldozer mediante dos buses de lectura de 128 bit y un bus de escritura de 128 bit. Se me antoja una mejora absolutamente espectacular respecto a anteriores diseños de AMD (un Phenom II X6, por ejemplo, solamente cuenta con un bus de 64 bit por core hacia y desde la L3 de 6 MB y 24 vías). De ahí sus mediocres resultados en este apartado.
Especulación 1. Espero latencias L3 elevadas en Bulldozer.
Teniendo en cuanta que la latencia efectiva L3 (load to use) es aditiva con la de los demás niveles y que la latencia L2 ya es conocida y va de los 18 a los 20 ciclos no será nada extraño que la latencia L3 efectiva en Bulldozer ronde los 50 ciclos.
Otro dato que apunta en la misma dirección es que se mantiene el diseño asíncrono con buffers de sincronización de Shanghai (Phenom II 45 nm), con una frecuencia de cores variable por los modos Turbo desde los 2.8 hasta los 3.5 GHz, será difícil conseguir bajas latencias L3.
Por último, una asociatividad tan elevada, 64 vías, aunque aumenta la tasa de aciertos L3, tampoco ayuda en cuanto a la latencia ya que hay que examinar 64 localizaciones cada vez en busca del dato o instrucción.
8 MB = 4 bancos de 2 MB y 16 vías
Una solución elegante que podría haber adoptado AMD consiste en que cada core tenga una latencia reducida de acceso hacia su banco local L3, es decir, que tenga “privilegio” de acceso a este banco y por ello mayor ancho de banda en GB/s y menor latencia en ciclos.
Conclusiones
AMD ha diseñado una caché L3 que marca un punto de partida desde sus actuales diseños de 45 nm y 6MB con 24 vías (Shanghai o Istambul). En Bulldozer son 4 bancos de 2 MB y 16 vías para un total de 64 vías.
Tengo ganas de probar un stepping final para ver si la latencia a cada uno de los bancos es diferente o por el contrario idéntica. Si existe una controladora de L3 para los 4 bancos será una latencia constante y elevada… en cambio, si cuenta (como Sandy Bridge) con una controladora L3 por cada banco de 2 MB pueden haber sorpresas.
En todo caso y con una L2 con 18 – 20 ciclos es difícil lograr latencias l3 muy recortadas. E s lógico esperar 10 ciclos más de latencia que en Sandy Bridge como mínimo (la L2 de SB tiene pipelines de 10 etapas Load to Use).
Destaca su optimización pensando en una baja disipación térmica y sobretodo en un consumo reducido, por ello su frecuencia rondará los 2.4 GHz y su voltaje estará sobre los 1.15 a 1.20 V efectivos. Es un diseño convencional, de bus con conectividad total entre todos los agentes, cada módulo Bulldozer y cada slice L3.
Hay que ser consciente del camino absolutamente divergente que ha adoptado Intel con Sandy Bridge 32 nm. La L3 es síncrona a los cores y funciona a la misma frecuencia que estos. Con ello consigue una bajísima latencia y un ancho de banda astronómico. Los diferentes bancos L3 se comunican entre sí mediante un ring bus bidireccional que aporta un gran ancho de banda y un funcionamiento “sencillo” a estos niveles.
AMD AGLUs, Bulldozer INT cores.
En este técnico artículo voy a detallar la estructura de los pipelines de ejecución de los INT cores duales de un módulo del nuevo procesador AMD Bulldozer.
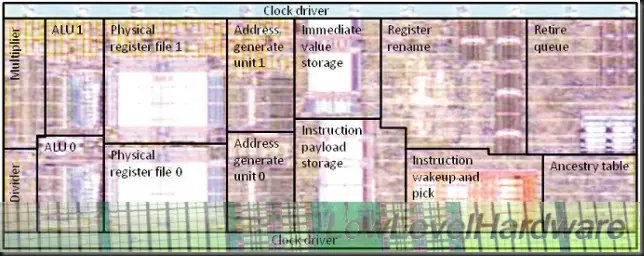
AMD Bulldozer. Filosofía de diseño.
Con Bulldozer AMD ha roto con el diseño “convencional” para el núcleo de procesamiento. Hasta ahora, un procesador era un bloque que trabajaba conjunta y síncronamente compuesto de varias subunidades.
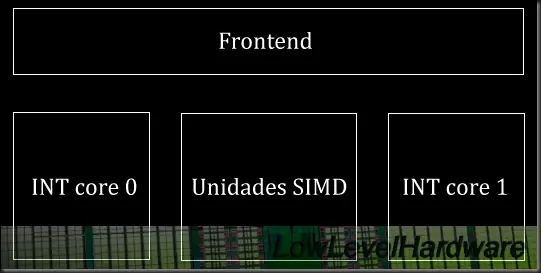
En cambio en Bulldozer, AMD ha seguido un diseño CMT (Cluster Multi Processing) de coprocesamiento con subunidades independientes y con pipelines desacoplados mediante buffers y queues.
Las ventaja principal de esta disposición reside en la compartición de algunas estructuras entre los dos cores de enteros. Cada core ejecuta un thread, cada thread debería afinitizarse a un core para dar un óptimo rendimiento.
Aunque alguna de las unidades esté bloqueada procesando datos el Front End sigue ejecutando Fetching y computando los Branches llenando sus queues (colas) y buffers con resultados.
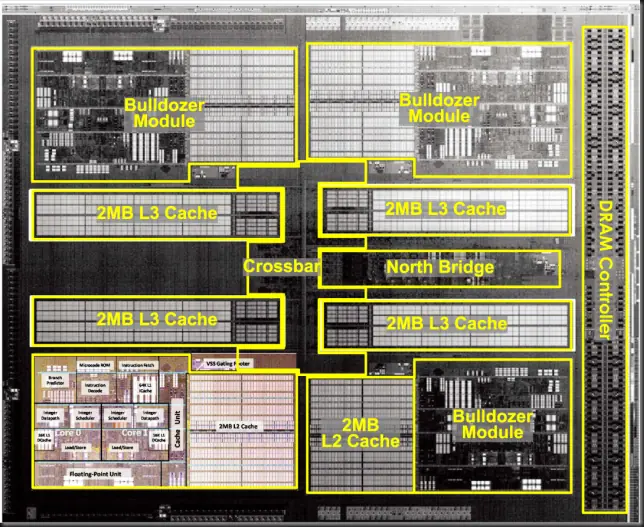
Resumiendo, con Bulldozer AMD construye un procesador multicore de 8 núcleos partiendo de una unidad que llaman el módulo que incluye 2 INT cores, la unidad SIMD y la L2 de 2 MB y 16 vías.
AMD Bulldozer Front End.
El frontend de Bulldozer es compartido por todas las subunidades y está dimensionado y lógicamente desacoplado de las unidades de ejecución.
Cada módulo contiene un sólo Front End que da servicio a tres unidades de ejecución:
Los dos INT cores con 4 pipelines de ejecución cada uno y con su Scheduler y Register File privados.
La unidad SIMD compartida (llamada desacertadamente por AMD y la prensa especializada FPU compartida) con su Schedule y Register File.
Yo la llamo unidad SIMD porque no sólo incluye (como detallaré en otro artículo) dos pipelines SIMD SSE, AVX y X87 sino también 2 unidades de 128 bit SIMD de enteros SSE y MMX (INT SIMD SSE y MMX).
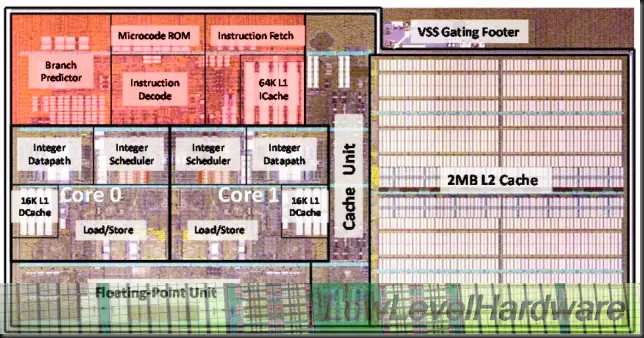
El Front End contiene entre otros:
La lógica de Branch Prediction que ha sido considerablemente rediseñada y ampliada de cara a aumentar su tasa de aciertos. Cuenta con un BTB de 2 niveles con miss penalties (penalización de fallo) de 15 a 20 ciclos en función del tipo de Branch.
Las etapas de fetching y decoding cargan datos (32 bytes/ciclo) desde las cachés L1i (64 KB, 2 vías) y alimentan dos ventanas de 16 bytes (una por thread). Hay un IBB (Instruction Byte Buffers) de 16 niveles en la cola de fetching por thread (2 IBBs, con cada 16 bytes por nivel).
Los Decoders pueden decodificar hasta 4 instrucciones / ciclo desde los IBB, cada ciclo se escanean dos de las ventanas de 16 bytes en busca de hasta cuatro instrucciones. En caso de instrucciones X86 complejas que hagan recurrir al Microcode Engine solamente se decodifica una instrucción por ciclo.
Bulldozer INT cores. Unidades de enteros.
Cada unidad de enteros es como un pequeño core de ejecución de 64 bit con 4 pipelines discretos alimentados por un Scheduler independiente.
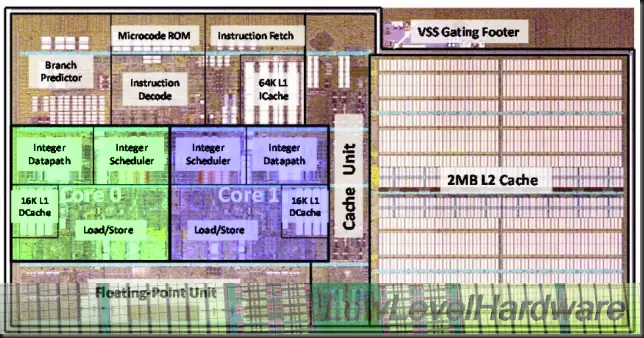
El núcleo de ejecución consta de 4 pipelines de 64 bit con un diseño peculiar y novedoso que incluye las unidades combinadas AGLU:

La longitud de los pipelines de enteros ha crecido en Bulldozer de un modo espectacular hasta las 18 o 20 etapas. Comparado con las 12 etapas de AMD Phenom destaca como un diseño claramente dirigido a altas frecuencias que en mi modesta opinión sólo tiene sentido si supera con claridad los 4 GHz en modos Turbo para compensar su gran penalización en caso de fallo de predicción Branch.

Lo novedoso de los INT cores son sus unidades híbridas AGLU:
Son unidades AGU (de generación de direcciones de memoria, address generators) pero con funciones básicas ALU, es decir, pueden procesar instrucciones simples ALU (LEA 64, INC) echando una mano para compensar el escaso ancho de proceso del core.
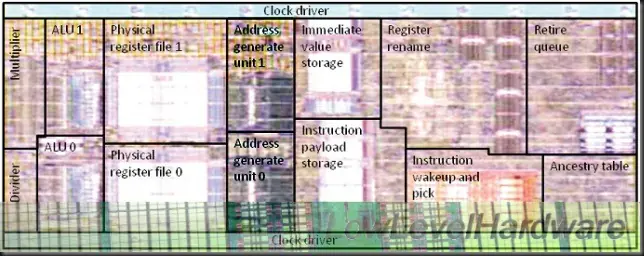
Las unidades de ejecución completas (Full ALU) EX0 y EX1 incluyen hardware específico para IMUL e IDIV:
EX0 contiene una unidad de división de enteros parcialmente pipelinizada y con latencia y capacidad de proceso variable en función de la precisión. Aunque examinando detenidamente la documentación parece que más bien se trata de una unidad “virtual” ya que la instrucción IDIV se decodifica en el Microcode Engine y se secuencia en instrucciones sencillas ALU que se ejecutan en EX0. Además incluye una unidad para LZCNT y POPCNT.
EX1 por su parte contiene un rapidísimo multiplicador de enteros pipelinizado y de bajísima latencia.
Ambas unidades procesan Branches e instrucciones de enteros complejas.
Cada INT core cuenta con su Scheduler discreto e independiente y ejecuta un thread, además supervisa el procesamiento en las unidad SIMD compartida de las instrucciones FPU X87, FPU SIMD SSE / AVX o INT SIMD MMX / SSE.
Conclusiones
El diseño de Bulldozer me deja un sabor agridulce, AMD sin duda ha dado un paso adelante y si consigue ponerlo en el mercado a frecuencias adecuadas (4 GHz o más en Turbo Mode) tendrá un procesador globalmente competitivo con Sandy Bridge.
Hay detalles que sinceramente no me acaban de convencer como algunas latencias muy elevadas en algunas instrucciones y sin duda será inferior a Sandy Bridge en proceso FPU AVX 256 bit.
Bulldozer puede ser un excelente procesador en cargas de enteros de 8 threads, queda la incógnita acerca del rendimiento de su caché L3 y el subsistema de memoria.
Las latencias L3 serán altas, creo que superiores a los 50 ciclos load to use, razonable me parecen 60 incluso. Hay que ver como compensa efectivamente el Hardware Prefetch este hecho. La elevada latencia L2 (de 18 a 20 ciclos) la compensa parcialmente su gran tamaño (Sandy Bridge se conforma con 256 KB, 8 veces menos, pero con latencias de 9-10 ciclos).
Tengamos en cuenta que la frecuencia del Uncore que incluye la caché L3 multibanco (4 bancos de 2 MB) de 8 MB será muy inferior a la de los cores, probablemente se mueva sobre los 2.4 – 2.66 GHz lo que afectará a la latencia L3 y de memoria.
El panorama en 2011 será divertido… nos vemos en la próxima entrega con un análisis de la unidad SIMD de 4 vías compartida de proceso FPU SSE / AVX / X87 y INT SIMD SSE / MMX.
Quieren ver el nuevo AM3+???????
Ultima data los bulldozer van a salir a la venta a mediados de septiembre ......y luego de 1 o 2 o 3 años la tecnología bulldozer se va a fusionar con la tecnología denominada llanos (la de la APU), próximamente vamos a tener un micro con núcleos super potentes integrados con una GPU increíble ojala que no se retrase demasiado aunque todavía falta mucho para eso.....................
La primera ola de procesadores AMD de la serie FX de alto rendimiento, llegará a las tiendas el 19 de septiembre de 2011, según confirmaron fuentes del sector. Ese día, AMD lanzará dos modelos de 8 núcleos: el FX-8100 y el FX 8150; un modelo de 6 núcleos, el FX-6100, y uno de 4 núcleos: FX-4100. El "FX-8130P" que ha sido un favorito de para las pantallas de CPU-Z, no será parte de la gama de AMD.
En el primer trimestre de 2012, AMD planea su segunda ronda de lanzamientos de productos, que consisten en modelos más rápidos. El FX-8170 desplazará a la FX-8150, el FX-8120 desplazara al FX-8100, el FX-6120 al FX-6100 y el FX-4120 al FX-4100. Mientras tanto, AMD está trabajando con los fabricantes de placas base para garantizar la propagación de las placas base socket AM3 +, y lo más importante, para hacer que las memoria DDR3-1866 MHz sean más asequible, ya que los procesadores FX tienen un rendimiento más óptimo con esa velocidad de la memoria.
update
AMD Bulldozer. Perspectivas
Mucho se está hablando en los círculos informáticos acerca de la nueva micro arquitectura Bulldozer de AMD. Un diseño pensado para cargas de trabajo multithread y con pipelines de ejecución con mayor número de etapas para un alto potencial en frecuencia.

En este artículo expondré algunas de mis opiniones sobre la micro arquitectura que va a marcar el futuro inmediato AMD de aquí a 2014.
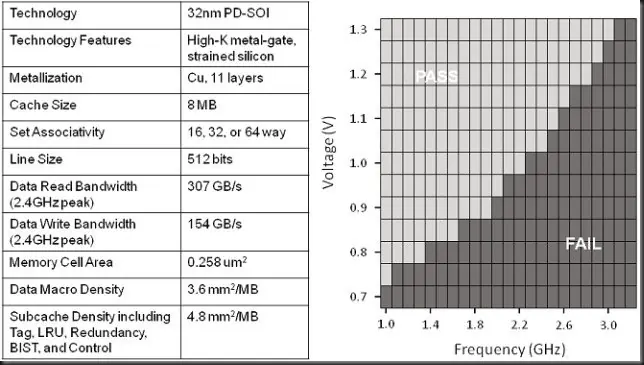
Bulldozer está fabricado por Global Foundries en el nodo de proceso de 32 nm HKMG (High K Metal Gate) SOI (Silicon On Insulator) lo que le dará unas buenas perspectivas de mejora de frecuencia y reducción de consumo con el paso del tiempo.
AMD a lo largo de su historia se ha caracterizado por ofrecer una continua mejora de su proceso de fabricación de semiconductores a los largo de la vida de cada nodo (para AMD unos 2 o 3 años).
Podemos decir que AMD saca al mercado los primeros chips en un nodo concreto (45 nm, 32 nm,…) cuando tiene unos yields (rendimientos de fabricación) mínimos (debido a la brutal presión competitiva de Intel) pero suficientes aún a costa de unas frecuencias de funcionamiento iniciales reducidas.
Con el paso de los meses AMD va mejorando paso a paso el proceso y se va reduciendo la disipación térmica, el voltaje y aumenta la frecuencia máxima de sus diseños.

AMD Orochi Bulldozer. 4 módulos, 8 INT cores, 4 dual 128 FMACs y 2 MB L2
AMD Orochi va a rondar los casi 300 mm2 y está constituido por:
4 módulos completos.
4 bancos L3 de 2 MB y 16 vías (para un total de 8 MB L3 con 64 vías)
4 buses HT 3.0
2 controladoras DDR3 1866 MHz.
Un North Bridge.
El módulo en AMD Bulldozer
Un módulo está integrado por:
2 INT cores con 2 ALUs y 2 AGUs, cada uno con su L1d de 16KB y 4 vías.
El Instruction Fetching desde la L1i compartida de 64KB y 2 vías.
La lógica de decoding de 4 vías con la Microcode ROM.
El circuitería de Branch Prediction.
La FPU doble de 128 bit FMAC (Fused Multiply Accumulate).
La unidad de control de caché que comprende las dos WCC (Write Combining Caches de 4 KB, una por INT core) que da acceso a la masiva cache L2 de 2 MB y 16 vías.
¿Qué podemos esperar de AMD Bulldozer?
Bulldozer al igual que Llano (la APU de 32 nm) se fabrican en el nuevo proceso y por ello sufrirán inicialmente de unas frecuencia máximas no muy elevadas.
Llano se ha estrenado a frecuencias máximas de 2.9 GHz, ahora está previsto que llegue al mercado una versión desbloqueada a 3.1 GHz con overclocks “sencillos” a 3.6 GHz.
Los cores de un Phenom II (al menos en los últimos steppings de 45 nm) llegan con relativa facilidad a los 4 GHz. A Llano esta frecuencia le queda lejos y eso que está fabricado en el siguiente nodo que debería proporcionar una mejora teórica de un 20% en frecuencia.

Recordemos que cuando AMD empezó a fabricar CPUs de 65 nm también padeció problemas claros de escalado de frecuencia, en concreto los primeros AMD K8 Brisbane funcionaban a 2.6 GHz cuando los “antiguos” K8 90 nm funcionaban sin problema a 3 GHz.
O pensemos en AMD Phenom Barcelona, fabricado en 65 nm en 2007 y que salió al mercado a unos meros 2.3 GHz cuando los K8 de la época (todavía de 90 nm) funcionaban a 3.2 GHz (Athlon 64 X2 6400+).
Conclusiones
Con esta coyuntura en mente podemos pensar lo siguiente según los diversos rumores y leaks que circulan:
Bulldozer, inicialmente en su configuración completa (Orochi) para socket AM3+ es deseable que ronde los 3.5 GHz nominales con carga 100% en los 8 cores y que gracias al Turbo logre frecuencias con carga de cores parcial (mitad de cores al 100%) rondando los 4 GHz.
AMD postula precios de unos 300 dólares para el top bin de Orochi, eso le sitúa en la banda de precios del Intel Core i7 2600K Sandy bridge: En mi opinión sería un éxito rotundo de AMD el posicionarse competitivamente en este nivel de precios.
A mí personalmente me cuesta creerlo pero sería una excelente noticia para la sana competencia en el sector.
En cualquier caso estamos a la vuelta de la esquina del lanzamiento previsto para Bulldozer, será en Septiembre si no hay cambio de planes. Para AMD sería una excelente noticia, y de paso dispararía su cotización bursátil, bastante deprimida tras los momentos gloriosos de los K7 y K8.
Estos días se está celebrando el HotChips 23, una de las convenciones anuales donde se discuten los nuevos diseños de procesadores de sobremesa, servidores, memorias, procesadores de bajo consumo para dispositivos móviles… todo lo relacionado con el mundo del silicio en 2011.
Y claro está, también ha habido alguna nueva información sobre Bulldozer y mucha viejas ideas “refritas” sobre este nuevo core. Lamentablemente, ninguna estimación prestacional, puro silicon para entendidos en la materia.
AMD ha entrado en detalle en algunos aspectos del diseño del chip Zambezi (4 módulos y 8 INT cores) fabricado por Global Foundries en 32 nm SOI HKMG.
Nuevas fotografías del die de Bulldozer
En este slide de la presentación en HotChips vemos una nueva toma del die de Bulldozer.

Aparece con mayor altura que en anteriores vistas, si comparáis con anteriores artículos míos veréis claramente la diferencia. No hay modo de saber cual es la correcta, si esta o las antiguas (más alargadas), hasta que haya samples comerciales.
Ampliación del die:
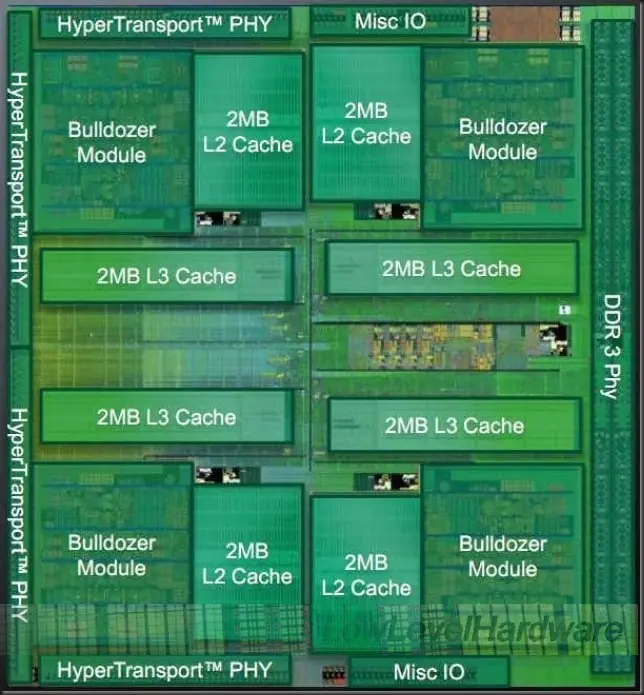
Lo que me llama poderosamente la atención es la grandísima cantidad de espacio desaprovechado: No utilizado ni por cores (lógica) ni cachés ni por las controladoras de memoria y buses Hyper Transport 3.
En varios de mis numerosos artículos sobre Intel Sandy Bridge, mencioné el enrutado de todo el cableado del Ring Bus bajo la caché L3. Todo este esfuerzo de ingeniería se realizó para ahorrar espacio de die y reducir el tamaño de Sandy Bridge. Cito textualmente (Extraído de Microarquitectura Intel Sandy Bridge. Parte 1. Actualizado – LowLevelHardware. Martes 14 de septiembre de 2010):
“ Lo más llamativo del bus en anillo de Sandy Bridge (y Nehalem EX) es su implementación respetuosa con el consumo y el área de die, me explico:
Todos recordamos el famoso procesador Radeon HD 2900 de ATI con un ring bus de 512 bits, que debido a su desmesurada disipación térmica y consumo no pudo competir con sus análogos de nVidia hasta que ATI lo eliminó sustituyéndolo por una arquitectura convencional en su serie Radeon HD 3800.
En Sandy Bridge Intel ha utilizado power gating y clock gating extensivamente, además de aplicar un voltaje bajísimo al ring bus para conseguir una disipación térmica muy baja.
Por otro lado, es un dato muy importante, según los ingenieros de Intel, no ha representado un incremento de área ya que la infinidad de conductores necesarios para el Ring Bus se enrutan por otras capas del diseño bajo la caché L3. “
AMD simplemente no dispone de los extensos recursos económicos y humanos de Intel y no puede permitirse el lujo de este tipo de optimizaciones, bastante tiene con llevar a cabo el diseño de un semiconductor de tal complejidad como Bulldozer.
Superficie del die de AMD Bulldozer
Por fin conocemos el verdadero tamaño de Bulldozer y debo decir que estoy algo decepcionado: nada menos que 315 mm2… muy caro de producir.
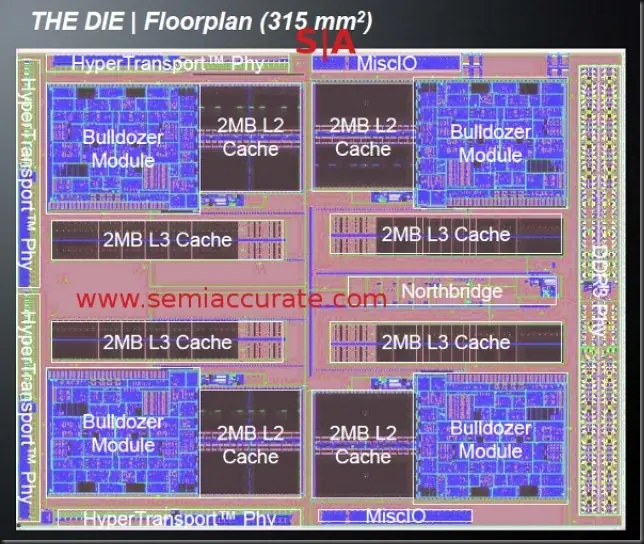
Estoy convencido de que AMD sin duda optimizará este diseño en sucesivas iteraciones (con el paso a 22 nm en un par de años) e incluso antes con el lanzamiento de la versión de 5 módulos y 20 cores producida también en 32 nm.
Infraestructura de AMD Zambezi. AM3+
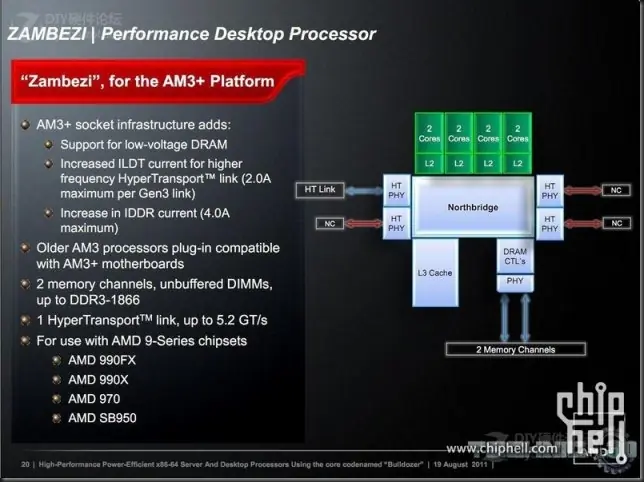
Como vemos la versión de sobremesa de Bulldozer solo activa uno de los 4 enlaces HT3 para comunicación con el chipset (los demás permanecen deshabilitados, en su versión Opteron se utilizan como conexión directa con hasta tres chips más).
La latencia L3 se me antoja como he comentado en numerosas ocasiones muy alta, creo firmemente que rondará los 50+ ciclos.
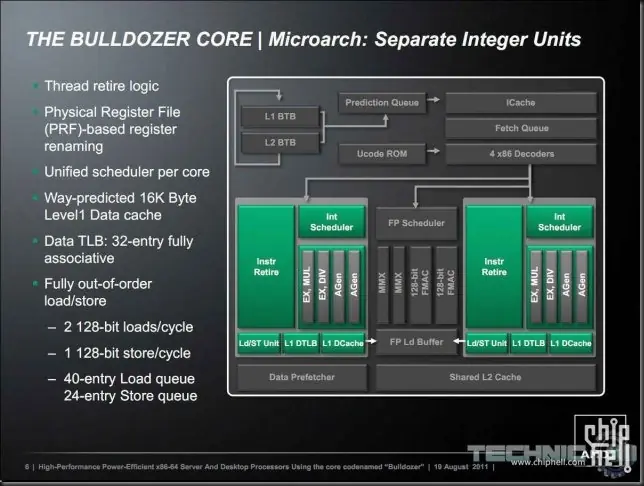
Ni rastro de las extrañas AGLU, ahora las llaman AGen, es decir una normal y corriente AGU. Además solamente hay dos pipes de enteros (INT pipes) una con circuitería MUL y la otra según AMD con un divisor por hardware (DIV). Viendo las latencias de división entera de Bulldozer me da la impresión de que tal divisor no existe y la división se ejecuta por micro código o tiene un diseño extremadamente simplificado y poco efectivo.
AMD Turbo Core en Bulldozer
En Bulldozer, AMD presenta un Turbo Core de dos niveles.

All Core Boost: Todos los módulos (conjuntos de dos cores con su SIMD FPU Unit y los 2 MB de L2) aumentan su frecuencia por encima de la nominal si el TDP y la temperatura lo permite.
Se da en cargas de trabajo que implique a TODOS los cores, sea con carga parcial elevada o máxima 100%.
Max Turbo Boost: Si dos de los módulos (cuatro INT cores, dos SIMD FPUs y dos L2 de 2 MB) se hallan en estado Sleep C6 (power gated) el resto (los otros dos módulos) pueden incrementar su frecuencia hasta en 1 GHz sobre la nominal.
Conclusiones
Poco se puede concluir hasta que no haya datos objetivos de steppings finales. Los actuales samples de Bulldozer son realmente lentos debido a numerosos bugs en los primeros steppings A y B1 que han hecho necesario deshabilitar características clave de las controladoras de memoria, cachés, TLBs, etc.
Queda ver como será Bulldozer con todos sus subsistemas a punto y cuales son las frecuencias finales comerciales. Sin duda estas no serán indicativas del verdadero potencial final en frecuencia de Bulldozer en 32 nm; AMD mejora sus procesos paso a paso a lo largo del tiempo en que este está en el mercado.
La historia fue realmente brillante en 90 nm cuando culminó en unos excelentes 3.2 GHz con el Athlon 64 X2 6400+ partiendo de los iniciales 1.8 GHz.
En el proceso de 65 nm SOI la historia fue diferente y empezó realmente mal. Los primeros Athlon 64 X2 eran claramente más lentos por ciclo (IPC) que los anteriores de 90 nm y les era imposible llegar a los 3 GHz. Con el tiempo llegaron a 3.1 GHz, un mal resultado e inferior al anterior de 90 nm SOI.
En aquel tiempo AMD lanzó Barcelona (Phenom) quad core también en 65 nm con unas frecuencias decepcionantes de 2.3 GHz en pico y una ridículamente pequeña caché L3 de 2 MB y elevada latencia. Con los meses llegó a 2.6 GHz y por fin llegaron los 45 nm.
Los 45 nm para AMD han sido un éxito rotundo, los Phenom II Shanghai subieron rápidamente de frecuencia y el incremento a 6M de la caché L3 le permitió ganar prestaciones por ciclo (IPC) respecto a Barcelona. A esto se añadió la excelente versión de 6 cores con Turbo Core, el Phenom II X6, también con 6 MB de L3.
Gracias al exitoso proceso de 45 nm AMD ha podido sobrevivir con un anticuado diseño de CPU que data de 2003, (remozado en 2007 con Barcelona, aunque igual en la parte de enteros) y esto lo escribo en Agosto de 2011…
Poco a poco se acerca la comercialización de los procesadores basados en la nueva micro arquitectura de AMD prevista para el 7 de junio. Actualización: finalmente llegará al mercado en Septiembre según los últimos roadmaps.
Conforme pasan los días se va filtrando nueva información sobre su estructura interna y también algunos datos acerca de su rendimiento, o por lo menos del rendimiento de algunos Engineering Samples.
En este artículo hablaré sobre la estructura de la caché L3 en Bulldozer y sobre su funcionamiento.
La caché L3 multibanco: 4 x 2 MB
AMD ha diseñado una caché L3 particionada en 4 sub arrays de 2 MB y 16 vías cada uno. la capacidad total en el chip de 4 módulos y 8 INT cores es de 8 MB y 64 vías de asociatividad.
El diseño es exclusivo, la L3 no incluye los datos presentes en la L2 de 2 MB de cada módulo y en cambio es una Victim Cache, donde se alojan las páginas desalojadas desde L2.
Con una frecuencia estimada en 2.4 GHz los anchos de banda son los siguientes:
307.2 GB/s en lectura gracias a sus dos accesos por ciclo de 128 bit y por módulo.
2 400 000 ciclos/s x 4 módulos x (2 accesos/ciclo x 128 bit) = 2 457 600 000 bit / 8bits/1 byte = 307 200 000 bytes/s = 307.2 GB/s
153.6 GB/s en escritura gracias al acceso de 128 bit por ciclo.
2 400 000 ciclos/s x 4 módulos x 128 bit = 1 228 800 000 bit / 8bits/1 byte =152 600 000 bytes/s = 153.6 GB/s
Por lo que se desprende de este documento, la caché L3 está conectada con cada módulo Bulldozer mediante dos buses de lectura de 128 bit y un bus de escritura de 128 bit. Se me antoja una mejora absolutamente espectacular respecto a anteriores diseños de AMD (un Phenom II X6, por ejemplo, solamente cuenta con un bus de 64 bit por core hacia y desde la L3 de 6 MB y 24 vías). De ahí sus mediocres resultados en este apartado.
Especulación 1. Espero latencias L3 elevadas en Bulldozer.
Teniendo en cuanta que la latencia efectiva L3 (load to use) es aditiva con la de los demás niveles y que la latencia L2 ya es conocida y va de los 18 a los 20 ciclos no será nada extraño que la latencia L3 efectiva en Bulldozer ronde los 50 ciclos.
Otro dato que apunta en la misma dirección es que se mantiene el diseño asíncrono con buffers de sincronización de Shanghai (Phenom II 45 nm), con una frecuencia de cores variable por los modos Turbo desde los 2.8 hasta los 3.5 GHz, será difícil conseguir bajas latencias L3.
Por último, una asociatividad tan elevada, 64 vías, aunque aumenta la tasa de aciertos L3, tampoco ayuda en cuanto a la latencia ya que hay que examinar 64 localizaciones cada vez en busca del dato o instrucción.
8 MB = 4 bancos de 2 MB y 16 vías
Una solución elegante que podría haber adoptado AMD consiste en que cada core tenga una latencia reducida de acceso hacia su banco local L3, es decir, que tenga “privilegio” de acceso a este banco y por ello mayor ancho de banda en GB/s y menor latencia en ciclos.
Conclusiones
AMD ha diseñado una caché L3 que marca un punto de partida desde sus actuales diseños de 45 nm y 6MB con 24 vías (Shanghai o Istambul). En Bulldozer son 4 bancos de 2 MB y 16 vías para un total de 64 vías.
Tengo ganas de probar un stepping final para ver si la latencia a cada uno de los bancos es diferente o por el contrario idéntica. Si existe una controladora de L3 para los 4 bancos será una latencia constante y elevada… en cambio, si cuenta (como Sandy Bridge) con una controladora L3 por cada banco de 2 MB pueden haber sorpresas.
En todo caso y con una L2 con 18 – 20 ciclos es difícil lograr latencias l3 muy recortadas. E s lógico esperar 10 ciclos más de latencia que en Sandy Bridge como mínimo (la L2 de SB tiene pipelines de 10 etapas Load to Use).
Destaca su optimización pensando en una baja disipación térmica y sobretodo en un consumo reducido, por ello su frecuencia rondará los 2.4 GHz y su voltaje estará sobre los 1.15 a 1.20 V efectivos. Es un diseño convencional, de bus con conectividad total entre todos los agentes, cada módulo Bulldozer y cada slice L3.
Hay que ser consciente del camino absolutamente divergente que ha adoptado Intel con Sandy Bridge 32 nm. La L3 es síncrona a los cores y funciona a la misma frecuencia que estos. Con ello consigue una bajísima latencia y un ancho de banda astronómico. Los diferentes bancos L3 se comunican entre sí mediante un ring bus bidireccional que aporta un gran ancho de banda y un funcionamiento “sencillo” a estos niveles.
AMD AGLUs, Bulldozer INT cores.
En este técnico artículo voy a detallar la estructura de los pipelines de ejecución de los INT cores duales de un módulo del nuevo procesador AMD Bulldozer.
AMD Bulldozer. Filosofía de diseño.
Con Bulldozer AMD ha roto con el diseño “convencional” para el núcleo de procesamiento. Hasta ahora, un procesador era un bloque que trabajaba conjunta y síncronamente compuesto de varias subunidades.
En cambio en Bulldozer, AMD ha seguido un diseño CMT (Cluster Multi Processing) de coprocesamiento con subunidades independientes y con pipelines desacoplados mediante buffers y queues.
Las ventaja principal de esta disposición reside en la compartición de algunas estructuras entre los dos cores de enteros. Cada core ejecuta un thread, cada thread debería afinitizarse a un core para dar un óptimo rendimiento.
Aunque alguna de las unidades esté bloqueada procesando datos el Front End sigue ejecutando Fetching y computando los Branches llenando sus queues (colas) y buffers con resultados.
Resumiendo, con Bulldozer AMD construye un procesador multicore de 8 núcleos partiendo de una unidad que llaman el módulo que incluye 2 INT cores, la unidad SIMD y la L2 de 2 MB y 16 vías.
AMD Bulldozer Front End.
El frontend de Bulldozer es compartido por todas las subunidades y está dimensionado y lógicamente desacoplado de las unidades de ejecución.
Cada módulo contiene un sólo Front End que da servicio a tres unidades de ejecución:
Los dos INT cores con 4 pipelines de ejecución cada uno y con su Scheduler y Register File privados.
La unidad SIMD compartida (llamada desacertadamente por AMD y la prensa especializada FPU compartida) con su Schedule y Register File.
Yo la llamo unidad SIMD porque no sólo incluye (como detallaré en otro artículo) dos pipelines SIMD SSE, AVX y X87 sino también 2 unidades de 128 bit SIMD de enteros SSE y MMX (INT SIMD SSE y MMX).
El Front End contiene entre otros:
La lógica de Branch Prediction que ha sido considerablemente rediseñada y ampliada de cara a aumentar su tasa de aciertos. Cuenta con un BTB de 2 niveles con miss penalties (penalización de fallo) de 15 a 20 ciclos en función del tipo de Branch.
Las etapas de fetching y decoding cargan datos (32 bytes/ciclo) desde las cachés L1i (64 KB, 2 vías) y alimentan dos ventanas de 16 bytes (una por thread). Hay un IBB (Instruction Byte Buffers) de 16 niveles en la cola de fetching por thread (2 IBBs, con cada 16 bytes por nivel).
Los Decoders pueden decodificar hasta 4 instrucciones / ciclo desde los IBB, cada ciclo se escanean dos de las ventanas de 16 bytes en busca de hasta cuatro instrucciones. En caso de instrucciones X86 complejas que hagan recurrir al Microcode Engine solamente se decodifica una instrucción por ciclo.
Bulldozer INT cores. Unidades de enteros.
Cada unidad de enteros es como un pequeño core de ejecución de 64 bit con 4 pipelines discretos alimentados por un Scheduler independiente.
El núcleo de ejecución consta de 4 pipelines de 64 bit con un diseño peculiar y novedoso que incluye las unidades combinadas AGLU:
La longitud de los pipelines de enteros ha crecido en Bulldozer de un modo espectacular hasta las 18 o 20 etapas. Comparado con las 12 etapas de AMD Phenom destaca como un diseño claramente dirigido a altas frecuencias que en mi modesta opinión sólo tiene sentido si supera con claridad los 4 GHz en modos Turbo para compensar su gran penalización en caso de fallo de predicción Branch.
Lo novedoso de los INT cores son sus unidades híbridas AGLU:
Son unidades AGU (de generación de direcciones de memoria, address generators) pero con funciones básicas ALU, es decir, pueden procesar instrucciones simples ALU (LEA 64, INC) echando una mano para compensar el escaso ancho de proceso del core.
Las unidades de ejecución completas (Full ALU) EX0 y EX1 incluyen hardware específico para IMUL e IDIV:
EX0 contiene una unidad de división de enteros parcialmente pipelinizada y con latencia y capacidad de proceso variable en función de la precisión. Aunque examinando detenidamente la documentación parece que más bien se trata de una unidad “virtual” ya que la instrucción IDIV se decodifica en el Microcode Engine y se secuencia en instrucciones sencillas ALU que se ejecutan en EX0. Además incluye una unidad para LZCNT y POPCNT.
EX1 por su parte contiene un rapidísimo multiplicador de enteros pipelinizado y de bajísima latencia.
Ambas unidades procesan Branches e instrucciones de enteros complejas.
Cada INT core cuenta con su Scheduler discreto e independiente y ejecuta un thread, además supervisa el procesamiento en las unidad SIMD compartida de las instrucciones FPU X87, FPU SIMD SSE / AVX o INT SIMD MMX / SSE.
Conclusiones
El diseño de Bulldozer me deja un sabor agridulce, AMD sin duda ha dado un paso adelante y si consigue ponerlo en el mercado a frecuencias adecuadas (4 GHz o más en Turbo Mode) tendrá un procesador globalmente competitivo con Sandy Bridge.
Hay detalles que sinceramente no me acaban de convencer como algunas latencias muy elevadas en algunas instrucciones y sin duda será inferior a Sandy Bridge en proceso FPU AVX 256 bit.
Bulldozer puede ser un excelente procesador en cargas de enteros de 8 threads, queda la incógnita acerca del rendimiento de su caché L3 y el subsistema de memoria.
Las latencias L3 serán altas, creo que superiores a los 50 ciclos load to use, razonable me parecen 60 incluso. Hay que ver como compensa efectivamente el Hardware Prefetch este hecho. La elevada latencia L2 (de 18 a 20 ciclos) la compensa parcialmente su gran tamaño (Sandy Bridge se conforma con 256 KB, 8 veces menos, pero con latencias de 9-10 ciclos).
Tengamos en cuenta que la frecuencia del Uncore que incluye la caché L3 multibanco (4 bancos de 2 MB) de 8 MB será muy inferior a la de los cores, probablemente se mueva sobre los 2.4 – 2.66 GHz lo que afectará a la latencia L3 y de memoria.
El panorama en 2011 será divertido… nos vemos en la próxima entrega con un análisis de la unidad SIMD de 4 vías compartida de proceso FPU SSE / AVX / X87 y INT SIMD SSE / MMX.
Quieren ver el nuevo AM3+???????
Ultima data los bulldozer van a salir a la venta a mediados de septiembre ......y luego de 1 o 2 o 3 años la tecnología bulldozer se va a fusionar con la tecnología denominada llanos (la de la APU), próximamente vamos a tener un micro con núcleos super potentes integrados con una GPU increíble ojala que no se retrase demasiado aunque todavía falta mucho para eso.....................
La primera ola de procesadores AMD de la serie FX de alto rendimiento, llegará a las tiendas el 19 de septiembre de 2011, según confirmaron fuentes del sector. Ese día, AMD lanzará dos modelos de 8 núcleos: el FX-8100 y el FX 8150; un modelo de 6 núcleos, el FX-6100, y uno de 4 núcleos: FX-4100. El "FX-8130P" que ha sido un favorito de para las pantallas de CPU-Z, no será parte de la gama de AMD.
En el primer trimestre de 2012, AMD planea su segunda ronda de lanzamientos de productos, que consisten en modelos más rápidos. El FX-8170 desplazará a la FX-8150, el FX-8120 desplazara al FX-8100, el FX-6120 al FX-6100 y el FX-4120 al FX-4100. Mientras tanto, AMD está trabajando con los fabricantes de placas base para garantizar la propagación de las placas base socket AM3 +, y lo más importante, para hacer que las memoria DDR3-1866 MHz sean más asequible, ya que los procesadores FX tienen un rendimiento más óptimo con esa velocidad de la memoria.
update
AMD Bulldozer. Perspectivas
Mucho se está hablando en los círculos informáticos acerca de la nueva micro arquitectura Bulldozer de AMD. Un diseño pensado para cargas de trabajo multithread y con pipelines de ejecución con mayor número de etapas para un alto potencial en frecuencia.
En este artículo expondré algunas de mis opiniones sobre la micro arquitectura que va a marcar el futuro inmediato AMD de aquí a 2014.
Bulldozer está fabricado por Global Foundries en el nodo de proceso de 32 nm HKMG (High K Metal Gate) SOI (Silicon On Insulator) lo que le dará unas buenas perspectivas de mejora de frecuencia y reducción de consumo con el paso del tiempo.
AMD a lo largo de su historia se ha caracterizado por ofrecer una continua mejora de su proceso de fabricación de semiconductores a los largo de la vida de cada nodo (para AMD unos 2 o 3 años).
Podemos decir que AMD saca al mercado los primeros chips en un nodo concreto (45 nm, 32 nm,…) cuando tiene unos yields (rendimientos de fabricación) mínimos (debido a la brutal presión competitiva de Intel) pero suficientes aún a costa de unas frecuencias de funcionamiento iniciales reducidas.
Con el paso de los meses AMD va mejorando paso a paso el proceso y se va reduciendo la disipación térmica, el voltaje y aumenta la frecuencia máxima de sus diseños.
AMD Orochi Bulldozer. 4 módulos, 8 INT cores, 4 dual 128 FMACs y 2 MB L2
AMD Orochi va a rondar los casi 300 mm2 y está constituido por:
4 módulos completos.
4 bancos L3 de 2 MB y 16 vías (para un total de 8 MB L3 con 64 vías)
4 buses HT 3.0
2 controladoras DDR3 1866 MHz.
Un North Bridge.
El módulo en AMD Bulldozer
Un módulo está integrado por:
2 INT cores con 2 ALUs y 2 AGUs, cada uno con su L1d de 16KB y 4 vías.
El Instruction Fetching desde la L1i compartida de 64KB y 2 vías.
La lógica de decoding de 4 vías con la Microcode ROM.
El circuitería de Branch Prediction.
La FPU doble de 128 bit FMAC (Fused Multiply Accumulate).
La unidad de control de caché que comprende las dos WCC (Write Combining Caches de 4 KB, una por INT core) que da acceso a la masiva cache L2 de 2 MB y 16 vías.
¿Qué podemos esperar de AMD Bulldozer?
Bulldozer al igual que Llano (la APU de 32 nm) se fabrican en el nuevo proceso y por ello sufrirán inicialmente de unas frecuencia máximas no muy elevadas.
Llano se ha estrenado a frecuencias máximas de 2.9 GHz, ahora está previsto que llegue al mercado una versión desbloqueada a 3.1 GHz con overclocks “sencillos” a 3.6 GHz.
Los cores de un Phenom II (al menos en los últimos steppings de 45 nm) llegan con relativa facilidad a los 4 GHz. A Llano esta frecuencia le queda lejos y eso que está fabricado en el siguiente nodo que debería proporcionar una mejora teórica de un 20% en frecuencia.
Recordemos que cuando AMD empezó a fabricar CPUs de 65 nm también padeció problemas claros de escalado de frecuencia, en concreto los primeros AMD K8 Brisbane funcionaban a 2.6 GHz cuando los “antiguos” K8 90 nm funcionaban sin problema a 3 GHz.
O pensemos en AMD Phenom Barcelona, fabricado en 65 nm en 2007 y que salió al mercado a unos meros 2.3 GHz cuando los K8 de la época (todavía de 90 nm) funcionaban a 3.2 GHz (Athlon 64 X2 6400+).
Conclusiones
Con esta coyuntura en mente podemos pensar lo siguiente según los diversos rumores y leaks que circulan:
Bulldozer, inicialmente en su configuración completa (Orochi) para socket AM3+ es deseable que ronde los 3.5 GHz nominales con carga 100% en los 8 cores y que gracias al Turbo logre frecuencias con carga de cores parcial (mitad de cores al 100%) rondando los 4 GHz.
AMD postula precios de unos 300 dólares para el top bin de Orochi, eso le sitúa en la banda de precios del Intel Core i7 2600K Sandy bridge: En mi opinión sería un éxito rotundo de AMD el posicionarse competitivamente en este nivel de precios.
A mí personalmente me cuesta creerlo pero sería una excelente noticia para la sana competencia en el sector.
En cualquier caso estamos a la vuelta de la esquina del lanzamiento previsto para Bulldozer, será en Septiembre si no hay cambio de planes. Para AMD sería una excelente noticia, y de paso dispararía su cotización bursátil, bastante deprimida tras los momentos gloriosos de los K7 y K8.
Estos días se está celebrando el HotChips 23, una de las convenciones anuales donde se discuten los nuevos diseños de procesadores de sobremesa, servidores, memorias, procesadores de bajo consumo para dispositivos móviles… todo lo relacionado con el mundo del silicio en 2011.
Y claro está, también ha habido alguna nueva información sobre Bulldozer y mucha viejas ideas “refritas” sobre este nuevo core. Lamentablemente, ninguna estimación prestacional, puro silicon para entendidos en la materia.
AMD ha entrado en detalle en algunos aspectos del diseño del chip Zambezi (4 módulos y 8 INT cores) fabricado por Global Foundries en 32 nm SOI HKMG.
Nuevas fotografías del die de Bulldozer
En este slide de la presentación en HotChips vemos una nueva toma del die de Bulldozer.
Aparece con mayor altura que en anteriores vistas, si comparáis con anteriores artículos míos veréis claramente la diferencia. No hay modo de saber cual es la correcta, si esta o las antiguas (más alargadas), hasta que haya samples comerciales.
Ampliación del die:
Lo que me llama poderosamente la atención es la grandísima cantidad de espacio desaprovechado: No utilizado ni por cores (lógica) ni cachés ni por las controladoras de memoria y buses Hyper Transport 3.
En varios de mis numerosos artículos sobre Intel Sandy Bridge, mencioné el enrutado de todo el cableado del Ring Bus bajo la caché L3. Todo este esfuerzo de ingeniería se realizó para ahorrar espacio de die y reducir el tamaño de Sandy Bridge. Cito textualmente (Extraído de Microarquitectura Intel Sandy Bridge. Parte 1. Actualizado – LowLevelHardware. Martes 14 de septiembre de 2010):
“ Lo más llamativo del bus en anillo de Sandy Bridge (y Nehalem EX) es su implementación respetuosa con el consumo y el área de die, me explico:
Todos recordamos el famoso procesador Radeon HD 2900 de ATI con un ring bus de 512 bits, que debido a su desmesurada disipación térmica y consumo no pudo competir con sus análogos de nVidia hasta que ATI lo eliminó sustituyéndolo por una arquitectura convencional en su serie Radeon HD 3800.
En Sandy Bridge Intel ha utilizado power gating y clock gating extensivamente, además de aplicar un voltaje bajísimo al ring bus para conseguir una disipación térmica muy baja.
Por otro lado, es un dato muy importante, según los ingenieros de Intel, no ha representado un incremento de área ya que la infinidad de conductores necesarios para el Ring Bus se enrutan por otras capas del diseño bajo la caché L3. “
AMD simplemente no dispone de los extensos recursos económicos y humanos de Intel y no puede permitirse el lujo de este tipo de optimizaciones, bastante tiene con llevar a cabo el diseño de un semiconductor de tal complejidad como Bulldozer.
Superficie del die de AMD Bulldozer
Por fin conocemos el verdadero tamaño de Bulldozer y debo decir que estoy algo decepcionado: nada menos que 315 mm2… muy caro de producir.
Estoy convencido de que AMD sin duda optimizará este diseño en sucesivas iteraciones (con el paso a 22 nm en un par de años) e incluso antes con el lanzamiento de la versión de 5 módulos y 20 cores producida también en 32 nm.
Infraestructura de AMD Zambezi. AM3+
Como vemos la versión de sobremesa de Bulldozer solo activa uno de los 4 enlaces HT3 para comunicación con el chipset (los demás permanecen deshabilitados, en su versión Opteron se utilizan como conexión directa con hasta tres chips más).
La latencia L3 se me antoja como he comentado en numerosas ocasiones muy alta, creo firmemente que rondará los 50+ ciclos.
Ni rastro de las extrañas AGLU, ahora las llaman AGen, es decir una normal y corriente AGU. Además solamente hay dos pipes de enteros (INT pipes) una con circuitería MUL y la otra según AMD con un divisor por hardware (DIV). Viendo las latencias de división entera de Bulldozer me da la impresión de que tal divisor no existe y la división se ejecuta por micro código o tiene un diseño extremadamente simplificado y poco efectivo.
AMD Turbo Core en Bulldozer
En Bulldozer, AMD presenta un Turbo Core de dos niveles.
All Core Boost: Todos los módulos (conjuntos de dos cores con su SIMD FPU Unit y los 2 MB de L2) aumentan su frecuencia por encima de la nominal si el TDP y la temperatura lo permite.
Se da en cargas de trabajo que implique a TODOS los cores, sea con carga parcial elevada o máxima 100%.
Max Turbo Boost: Si dos de los módulos (cuatro INT cores, dos SIMD FPUs y dos L2 de 2 MB) se hallan en estado Sleep C6 (power gated) el resto (los otros dos módulos) pueden incrementar su frecuencia hasta en 1 GHz sobre la nominal.
Conclusiones
Poco se puede concluir hasta que no haya datos objetivos de steppings finales. Los actuales samples de Bulldozer son realmente lentos debido a numerosos bugs en los primeros steppings A y B1 que han hecho necesario deshabilitar características clave de las controladoras de memoria, cachés, TLBs, etc.
Queda ver como será Bulldozer con todos sus subsistemas a punto y cuales son las frecuencias finales comerciales. Sin duda estas no serán indicativas del verdadero potencial final en frecuencia de Bulldozer en 32 nm; AMD mejora sus procesos paso a paso a lo largo del tiempo en que este está en el mercado.
La historia fue realmente brillante en 90 nm cuando culminó en unos excelentes 3.2 GHz con el Athlon 64 X2 6400+ partiendo de los iniciales 1.8 GHz.
En el proceso de 65 nm SOI la historia fue diferente y empezó realmente mal. Los primeros Athlon 64 X2 eran claramente más lentos por ciclo (IPC) que los anteriores de 90 nm y les era imposible llegar a los 3 GHz. Con el tiempo llegaron a 3.1 GHz, un mal resultado e inferior al anterior de 90 nm SOI.
En aquel tiempo AMD lanzó Barcelona (Phenom) quad core también en 65 nm con unas frecuencias decepcionantes de 2.3 GHz en pico y una ridículamente pequeña caché L3 de 2 MB y elevada latencia. Con los meses llegó a 2.6 GHz y por fin llegaron los 45 nm.
Los 45 nm para AMD han sido un éxito rotundo, los Phenom II Shanghai subieron rápidamente de frecuencia y el incremento a 6M de la caché L3 le permitió ganar prestaciones por ciclo (IPC) respecto a Barcelona. A esto se añadió la excelente versión de 6 cores con Turbo Core, el Phenom II X6, también con 6 MB de L3.
Gracias al exitoso proceso de 45 nm AMD ha podido sobrevivir con un anticuado diseño de CPU que data de 2003, (remozado en 2007 con Barcelona, aunque igual en la parte de enteros) y esto lo escribo en Agosto de 2011…