pablitoportillo9
Usuario (El Salvador)
En este post voy a tratar de documentar mi propia experiencia al instalar oracle 11g en open suse 12.2, como todo software robusto primero se debe preparar el entorno del sistema operativo para luego realizar la instalacion de manera mas sencilla y efectiva. Todo esto puede ser engorroso por la poca info en español la verdad al principio no se ve tan facil pero luego se vuelve mas digerible espero ayudar a alguno que haya tenido mi mismo problema al momento de la instalacion Primero lo primero....vamos a revisar los requisitos minimos generales del sistema para la instalacion del software en nuestro PC Minimos Requeridos 1 Gb de memoria RAM 1.5 Gb de Memoria Swap o de intercambio 1.5-3.5 Gb de Disco Duro (dependiendo del tipo de instalacion) - Abrir una consola: 1. Ingresar como usuario root $ su - root 2. Revisar cantidad de memoria RAM # grep MenTotal /proc/meminfo 3. Revisar cantidad de memoria swap # grep SwapTotal /proc/meninfo 4. Revisar cantidad de espacio libre en Disco duro # grep df -hk Si todo esto se cumple podemos continuar, cabe resaltar que personalmente instale oracle en una notebook con menos ram que la requeria alrededor de 1000 mb de ram y no 1024 :/ pero aun asi corre bastante bien, al principio lo corria con KDE pero definitivamente es mas veloz con GNOME - Para la instalacion de oracle 11g en suse se necesitan los siguientes paquetes, yo mismo pude verificar que basta con la version actual de dichos paquetes, ellos son: se pueden descargar por yast2 o zypper en la linea de comandos. binutils glibc libgcc libstdc++ gcc gcc-c++ glibc glibc-devel ksh-93r libaio libaio-devel libelf make sysstat unixODBC unixODBC-devel openmotif openmotif-libs - Ahora debemos crear la estructura de Usuarios y grupos sobre los que va a descarzar el software. 1. Creamos los grupos oinstall, dba, oper, asadmin # groupadd oinstall # groupadd dba # groupadd oper # groupadd asadmin 2. Ahora luego de eso creamos el usuario oracle y lo integramos a los grupos anteriores. # useradd -g oinstall -G dba, oper oracle # passwd oracle (este puede ser cualquier password) - Ahora a crear los directorios necesarios para la instalacion. Esta estructura es sacada del manual de oracle dba. #mkdir -p /u01/app/oracle/product/11.2.0(en nuestro caso)/db_1 y le asignamos como propietario al usuario oracle, luego le damos permisos. #chown -R oracle:oinstall /u01 #chmod -R 775 /u01 - Ahora vamos a editar algunos parametros del sistema: 1. vamos al fichero /etc/sysctl.conf con la ayuda de algun visor de consola como nano y al final del archivo agregamos los siguientes parametros: #config oracle fs.suid_dumpable = 1 fs.aio-max-nr = 1048576 fs.file-max = 6815744 kernel.shmall = 2097152 kernel.shmmax = 536870912 kernel.shmmni = 4096 # semaforos: semmsl, semmns, semopm, semmni kernel.sem = 250 32000 100 128 net.ipv4.ip_local_port_range = 9000 65500 net.core.rmem_default=4194304 net.core.rmem_max=4194304 net.core.wmem_default=262144 net.core.wmem_max=1048586 Luego ejecutamos este comando para cargar los parametros del kernel en caliente: # /sbin/sysctl -p -Proseguimos a modificar el archivo limist.conf para limitar el numero de procesos maximo y minimo entre otras cosas en el siguiente path nano /etc/security/limist.conf y agregamos la siguiente configuracion al final del archivo # configuracion Oracle oracle soft nproc 2047 oracle hard nproc 16384 oracle soft nofile 1024 oracle hard nofile 65536 oracle soft stack 10240 - Editamos el archivo: # nano /etc/pam.d/login y agregamos la siguiente linea al final del archivo session required /lib/security/pam_limits.so - vamos al nano /etc/profile y agregamos las siguientes lineas: if [ $USER = "oracle" ]; then if [ $SHELL = "/bin/ksh" ]; then ulimit -p 16384 ulimit -n 65536 else ulimit -u 16384 -n 65536 fi fi - Esta parte es opcional, vamos a cambiar la version del operativo ya que estamos sobre la version opensuse y esta no es soportada por oracle. puede que no paresca muy importante pero uno nunca sabe y realizarlo no esta de mas # mv /etc/SuSE-release /etc/SuSE-release.bkp # echo SuSE-9 > /etc/SuSE-release Bueno basta del usuario root ahora vamos a logearnos con el usario oracle que creamos antes, cabe resaltar que en el momento de logeo no debe de resultar ningun mensaje de error para poder continuar si es asi debemos revisar la escritura de la configuracion y ver si no ay algun error ahi, si todo esta bien proseguimos - Ahora proceguimos a logearnos como el usuario ORACLE # su - oracle 1. configuramos las variables de entorno necesarias para que oracle pueda trabajar de forma transparente. #nano .bashrc * El valor ORACLE_SID es el nombre de su base de datos! # Oracle Settings TMP=/tmp; export TMP TMPDIR=$TMP; export TMPDIR ORACLE_HOSTNAME=127.0.0.1; export ORACLE_HOSTNAME ORACLE_UNQNAME=DB11G; export ORACLE_UNQNAME ORACLE_BASE=/u01/app/oracle; export ORACLE_BASE ORACLE_HOME=$ORACLE_BASE/product/11.2.0/db_1; export ORACLE_HOME ORACLE_SID=orcl; export ORACLE_SID PATH=/usr/sbin:$PATH; export PATH PATH=$ORACLE_HOME/bin:$PATH; export PATH LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib; export LD_LIBRARY_PATH CLASSPATH=$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib; export CLASSPATH - En el archivo nano bash.profile agregamos: if [ -f ~/.bashrc ]; then source ~/.bashrc fi - Ahora descomprimimos los fuentes de oracle en una carpeta y le asignamos permisos de ejecucion y pertenencia al usuario oracle, tal y como lo hicimos antes..... Luego de esto solo queda la parte de la instalacion hasta ahora solo nos encargamos de preparar el entorno. cerramos cesion con el usuario oracle y la volvemos a abrir para ver que todo este bien y no nos de errores

Bueno recien instalado opensuse 12.2 me tope con el siguiente problema, la hora del sistema estaba erronea y utilizando el entorno grafico para cambiar la hora se consiguia pero al reiniciar se perdida la configuracion Para resolver este problema se debe realizar la configuracion como usuario root desde la linea de comando *Paso 1* Abrimos una terminal y nos logeamos como usuario root $ su - root *PAso 2* verificamos la fecha y hora actuales del sistema: # hwclock --show VEmos la fecha y la hora que tiene el sistema y seeguramente como en mi caso deberia estar retrasada como unas 5 o 6 horas, para remediar esto vamos a cambiar esta configuracion directamente como super usuario para que al reiniciar no se retomen otros valores. # hwclock --set --date="$(date "+4/6/2013 10:16:30" ) " reemplazen la fecha y hora por las respectivas y reinicien a mi me funciono
Pueden visitar el siguiente enlace donde se aprecian mejor las imagenes y el contenido! incluso pueden descargarlo cualquier duda estamos a la orden https://docs.google.com/file/d/0B-a4Fs4oAwJ9cE5TdWlrS0NiUWc/edit?pli=1 UNIVERSIDAD DE EL SALVADOR FACULTAD MULTIDICIPLINARIA DE OCCIDENTE NUEVO ISP BALANCEO DE CARGA Y CONTRO DEL FAIL OVER CATEDRA: COMUNICACIONES I CATEDRATICO: INGENIERO JUAN CARLOS PEÑA ALUMNOS: · HERBER OSWALDO GOMES ARANA · ISIDRO ANTONIO FLORES MARTINEZ · PABLO OSWALDO PORTILLO ALVARADO PLANTEAMIENTO DEL PROBLEMA. Una gran empresa está aburrida de perder tiempo de negocios por los fallos de su ISP y decide contratar un segundo proveedor que le permita acceso a los clientes a sus servicios. Ahora la empresa cuenta con dos proveedores de internet distintos, conectándose por medios redundantes a cada proveedor, pero no encuentra cómo configurar sus dispositivos de red para que de forma automática y transparente alterne los proveedores cuando uno u otro falle permitiendo seguir accediendo a sus servicios. En vista de lo anterior les contrata a ustedes como consultores para que realicen las configuraciones pertinentes. CONCEPTOS INTRODUCTORIOS Antes de dar solución a un problema es necesario saber de qué se trata y que es necesario conocer para resolverlo. Primeramente definimos que es un firewall. ¿QUE ES UN FIREWALL? Un firewall también es conocido como muro de fuego, este funciona entre las redes conectadas permitiendo o denegando las comunicaciones entre dichas redes. Un firewall también es considerado un filtro que controla el tráfico de varios protocolos como TCP/UDP/ICMP que pasan por el para permitir o denegar algún servicio, el firewall examina la petición y dependiendo de este lo puede bloquear o permitirle el acceso. Un firewall puede ser un dispositivo de tipo Hardware o software que se instala entre la conexión a Internet y las redes conectadas en el lugar. La Figura 1 ilustra un esquema común de firewall. Sea el tipo de firewall que sea, generalmente no tendrá más que un conjunto de reglas en las que se examina el origen y destino de los paquetes del protocolo tcp/ip. En cuanto a protocolos es probable que sean capaces de filtrar muchos tipos de ellos, no solo los tcp, también los udp, los icmp, los gre y otros protocolos vinculados a vpns. Este podría ser (en pseudo−lenguaje) un el conjunto de reglas de un firewall del primer gráfico: Política por defecto ACEPTAR. Todo lo que venga de la red local al firewall ACEPTAR Todo lo que venga de la ip de mi casa al puerto tcp 22 ACEPTAR Todo lo que venga del exterior al puerto tcp 1 al 1024 DENEGAR Todo lo que venga del exterior al puerto tcp 3389 DENEGAR Todo lo que venga del exterior al puerto udp 1 al 1024 DENEGAR Hay dos maneras de implementar un firewall: 1. Política por defecto ACEPTAR: en principio todo lo que entra y sale por el firewall se acepta y solo se denegará lo que se diga explícitamente. 2. Política por defecto DENEGAR: todo esta denegado, y solo se permitirá pasar por el firewall aquellos que se permita explícitamente. Un firewall ampliamente usado en distribuciones GNU/Linux es iptables en ipv4 e ip6tables en ipv6. IPTABLES Iptables permite al administrador del sistema definir reglas acerca de qué hacer con los paquetes de red. Las reglas se agrupan en cadenas: cada cadena es una lista ordenada de reglas. Las cadenas se agrupan en tablas: cada tabla está asociada con un tipo diferente de procesamiento de paquetes. Cada regla especifica que paquetes la cumplen (match) y un destino que indica que hacer con el paquete si este cumple la regla. Cada paquete de red que llega a una computadora o que se envía desde una computadora recorre por lo menos una cadena y cada regla de esa cadena se comprueba con el paquete. Si la regla cumple con el datagrama, el recorrido se detiene y el destino de la regla dicta lo que se debe hacer con el paquete. Si el paquete alcanza el n de una cadena predefinida sin haberse correspondido con ninguna regla de la cadena, la política de destino de la cadena dicta que hacer con el paquete. Si el paquete alcanza el fin de una cadena definida por el usuario sin haber cumplido ninguna regla de la cadena o si la cadena definida por el usuario está vacía, el recorrido continúa en la cadena que hizo la llamada (lo que se denomina implicit target RETURN o RETORNO de destino implícito). Solo las cadenas predefinidas tienen políticas. En iptables, las reglas se agrupan en cadenas. Una cadena es un conjunto de reglas para paquetes IP, que determinan lo que se debe hacer con ellos. BALANCEO DE CARGA La Solución de balanceo de carga permite dividir las tareas que tendría que soportar una única máquina, con el fin de maximizar las capacidades de proceso de datos, así como de ejecución de tareas. Esta Solución permite que ningún equipo sea parte vital del servicio que queremos ofrecer. De esta forma evitamos evitamos sufrir una parada del servicio debido a una parada de una de las maquinas. El balanceo de carga nos permite tener mayor ancho de banda; eso no significa que se tenga mayor velocidad de carga o descarga, si no que como se mencionó anteriormente, el trabajo se divide entre los IPS conectados, es decir que si se tienen 2 isps (como nuestro caso) el tráfico se distribuirá entre los 2 ISPś. NAT Usada cuando se desea hacer los paquetes sean enrutados a una máquina cliente dentro de una red local, pero también podremos enmascarar un red local y tener salida hacia internet. Una vez abordados los conceptos abordados previamente pasamos a dar solución a nuestra problemática. PRIMERA SOLUCION PLANTEADA Utilizando equipos con Sistema Operativo Linux Debian implementamos algunas herramientas que vienen compiladas en el kernel de Linux tales como Tablas de Ruteo , configuraciones de firewall NAT (ip tables) , Ruteo basado en políticas (ip rules), el demonio CRON y el comando “ip” para agregar rutas y modificarlas. La solución consiste básicamente en contar con un ISP principal y otro ISP de respaldo controlando el fail over (la caída) del ISP principal y reemplazarlo por ISP de respaldo, evitando así que la LAN interna se quede sin servicio de internet, todo esto de manera trasparente. Simulamos los Routers de ambos ISPś con 2 PC´s con sistema operativo Linux Mint utilizando una red cableada y otra red inalámbrica como salidas a internet, y un router de frontera que cuenta con SO Debian squeeze 6.0 para aplicar las configuraciones pertinentes. Diagrama de Red propuesto: Plan de direcciones · · · La LAN interna cuenta con este pool de direcciones 172.16.0.0/24, y cabe resaltar que el Router de frontera funciona como servidor DHCP ipv4. En el segmento entre el router de frontera y el ISP y RED CABLEADA tenemos la subred: 172.16.1.0/24. En el segmento entre el router de frontera y el isp RED INALAMBRICA tenemos la subred: 172.16.2.0/24. PROCEDIMIENTO. Las configuraciones se realizan en el router de frontera, dejamos a su criterio definir en que router implementara NAT, para nuestro caso lo colocamos en el router frontera. Básicamente modificamos los siguientes archivos en los cuales definimos las configuraciones pertinentes: 1. Configuración de interfaces de red. Para asignar direcciones ip a las interfaces de red de nuestra pc lo podemos hacer de 2 formas. I. Se pueden asignar direcciones a una interfaz escribiendo en la terminal lo siguiente. ifconfig ethn dirección_ip/marcada_subred up Donde n es el número de la interfaz que está conectada a nuestra pc, por ejemplo considere que se quiere asignar la dirección 172.16.1.1 que tiene una máscara de subred de 24 en la interfaz eth0, la manera de escribirlo sería ifconfig eth0 172.16.1.1/24 up; con esto se asigna la dirección a la interfaz, pero esta persiste solo mientras está encendida la pc, una vez se reinicia o se apaga, al configuración se pierde. II. Escribir en la terminal nano /etc/network/interfaces y se abrirá un archivo en la que configuraremos las interfaces a nuestro gusto. Utilizando la dirección e interfaz antes mencionada el archivo se tendría que configurar de la siguiente manera. auto eth0 iface eth0 inet static address 172.16.1.1 netmask 255.255.255.0 Una vez hecho esto damos ctrl+o para guardar y luego ctrl+x para salir. Ahora bien, ya tenemos asignada la dirección 172.16.1.1/24 a nuestra interfaz eth0 con lo que si la pc se apaga o se reinicia, la configuración no se pierde. Si quisiéramos recibir una dirección por DHCP simplemente escribimos iface eth0 inet dhcp, sin dirección ni mascara de subred. Para nuestro proyecto la forma en que quedarían configuradas las interfaces seria de la siguiente forma. #etho sale para tigo auto eth0 iface eth0 inet static address 172.16.1.1 netmask 255.255.255.0 #Claro auto eth1 iface eth1 inet static address 172.16.2.1 netmask 255.255.255.0 #LAN auto eth2 iface eth2 inet static address 172.16.0.1 netmask 255.255.255.0 2. Computadora como router. Para que nuestra computadora trabaje como router utilizando los sistemas operativos GNU/Linux es necesario modificar algunos archivos. Hay 2 formas de hacerlo. I. Escribir en la terminal “nano /proc/sys/net/ipv4/conf/all/forwarding” y se abrirá un archivo, por defecto este tiene valor de 0, lo editamos y lo cambiamos por el valor de 1, presionamos las teclas ctrl+o para guardar y luego ctrl+x para salir; con esto nuestra pc se convierte en Router mientras está encendida. Una vez se reinicia la PC o se apaga, esta configuración se pierde. Escribir en la terminal “nano /etc/sysctl.conf” y se abre un archivo, descomentamos lo siguiente para que nuestra computadora sea router y que no se pierda la configuración aunque la pc se reinicie o se apague. net.ipv4.ip_forward=1 3. Creación de tablas Ejecutamos en consola sudo nano /etc/iproute2/rt_tables en el cual se definen las tablas de ruteo del núcleo, por defecto este archivo cuenta con 3 tablas de ruteo, la main donde guarda las rutas por defecto, una para rutas broadcast y otra para multicast, aquí en este archivo definiremos 2 nuevas tablas de ruteo, una por cada ISPś. Las definimos como tabla tigo y tabla claro. La siguiente figura muestra la manera en la que quedaría el archivo de configuración rt_tables. II. 4. Regla NAT Editamos en consola /etc/rc.local. Este archivo se ejecuta en el arranque de Linux, los comandos colocados aquí se ejecutaran una vez al inicio del SO, nosotros lo utilizamos para definir las reglas de NAT con las cuales enmascararemos el tráfico de nuestra LAN con las ip's de los segmentos que se tienen con los ISPś. NAT básicamente reemplaza la ip de origen de cada paquete por la ip que nosotros definamos que puede ser una ip estática o una dinámica. La regla del NAT es como sigue. Iptables –t nat –A POSTROUTING –s dirección_origen_a convertir/marcara_subred interfaz_de_salida –j MASQUERADE Para nuestros propósitos escribimos la siguiente línea para salir a internet. Iptables –t nat –A POSTROUTING –s 172.16.2.0/24 –o eth0 –j MASQUERADE MASQUERADE automáticamente convierte nuestra IP de la red local a IP pública. El archivo queda como se muestra a continuación. –o 5. Configuración de reglas de navegación Configuramos las reglas de encaminamiento. Estas son las que escogen qué tabla de rutas se usa. Las ip rules nos permiten enrutar paquetes en base a su dirección de origen y destino, lo cual difiere de la forma tradicional de enrutado que solo toma en cuenta la dirección de destino. Una estructura de una regla seria como sigue. ip rule add from direccion_origen/mascara_subred priority prioridad_regla table nombre_tabla. Ejemplo. ip rule add from 172.16.0.0/24 priority 100 table tigo Las reglas de navegación han sido agregadas en el archivo /etc/network/interfaces. La siguiente se muestra a continuación; esta ira después de la configuración de las interfaces. Primeramente se definen las rutas y las reglas para la tabla tigo, posteriormente se definen las de la tabla claro. 6. Fail-Over Hasta aquí ya tenemos conectividad con internet utilizando el isp principal. El problema que aún no hemos resuelto tiene que ver con la caída ya sea del enlace con el isp principal o en su defecto la caída de la conectividad con internet, para explicarlo mejor podemos definir 2 casos que pueden darse: · · Problemas de conectividad en el enlace con el isp principal (problemas de cableado, problemas con las interfaces, problemas con el router del isp). Problemas de conectividad con internet (Puede darse el caso de que el enlace con el isp funcione bien pero no se tenga conexión con internet). Para resolver ambos problemas al mismo tiempo creamos un script que ejecuta comandos del Shell que detecta a través del uso de “ping” el fail-over (caida) ya sea del enlace con los ISPś o la conectividad con internet. El script reemplaza las ip rules que conducen el tráfico que viene de la LAN a salir por el ISPś principal por las ip rules que conducen el tráfico hacia el ISPś de respaldo, solo en caso de que alguna de las condiciones antes presentadas se den. El script queda como se detalla a continuación. 7. Script para supervicion de enlaces. El script /etc/crontab como tal resuelve nuestro problema de fail-over pero para hacerlo de manera transparente definimos en el archivo crontab que el script conectividad2.sh se ejecute cada 5 segundos, con este tiempo de retraso logramos detectar las caídas de los enlaces de forma casi instantánea. A continuación se muestra la forma en que queda configurado el script. Este script está definido para que se actualice cada 5 segundos, y que este supervisando los enlaces, de modo que si uno falla, automáticamente se pasa el tráfico para el otro enlace, siendo transparente para el usuario. Con los 7 pasos anteriormente descritos tenemos resolvemos al problema planteado, y nos aseguramos de estar conectados si uno u otro enlace falla. SEGUNDA SOLUCION Para nuestro propósito utilizaremos equipos con sistema operativo GNU/Linux y una distribución de FreeBSD llamada pfSense 2.0. Utilizamos pfSense para realizar Balanceo de Carga, NAT , reglas de firewall para bloquear algunas páginas web o determinados protocolos, DNS interno, proxy para filtrado de contenido, entre otras cosas. Para descargar pfSense e instalarlo puede visitar los siguientes enlaces. Descarga de pfSense: http://files.nyi.pfsense.org/mirror/downloads/ Para conocer la manera de como instalarlo puede visitar el siguiente enlace : http://alexalvarez0310.wordpress.com/category/portal-cautivo-con-pfsense/instalacion-de- pfsense/ Nota : Para instalar pfSense es necesario contar con 2 interfaces de red, una para la WAN y la otra para la LAN. Parar nuestros intereses utilizaremos 3 interfaces, 2 para las WAN y una para la LAN. Ingreso a pfSense. Una vez instalado el pfSense abrimos un navegador, nos conectamos con una computadora a una interfaz, nos asignamos una ip del mismo rango que la que tiene la interfaz y luego abrimos un navegador y escribimos la ip que tiene el pfSense en esa interfaz, nos cargara una página en la que es necesario loguearse. En username escribimos admin y en password escribimos pfSense. Configuración de interfaces. Primeramente es necesario configurar nuestras interfaces, para ello comenzamos configurando la interfaz para la WAN(conexión a internet 1) , nos vamos a la opción interfaces>WAN, la configuración necesaria para nuestros intereses seria como sigue. Ip estatica: 172.16.1.1 Gateway:172.16.1.2 Ahora configuramos la WAN2. La configuración queda como sigue. Ahora configuramos la LAN. La configuración queda como sigue. Hacemos click en el botón Save. 2. Verificar creación de Gatways. Nos vamos a la opción System>Routing>Gateways y verificamos que los gateways hayan sido creados correctamente. 3. Creación del grupo de Gateway. Para implementar el balanceo de carga primero debemos crear un grupo de Gateways, para ello nos vamos a la opción System>Routing>Groups, damos click en el símbolo + y nos aparecerá el siguiente menú: · · · Group Name: Nombre que identificara la unión de las conexiones WAN que se utilizara en configuraciones posteriores. Gateway Priority: Se especifica el tipo de prioridad que utilizaremos para cada conexión WAN, igual prioridad en ambas conexiones significará un balanceo de carga entre los ISP para la red de área local. Aqui se aplica el fail over Trigger Level: Momento en el que se aplicara el fail over , puede ser cuando un miembro s e caiga, cuando hayan paquetes perdidos, cuando haya alta latencia o cuando se de una combinación de las ultimas 2. La configuración debe quedar asi. Paso final para tener balanceo de carga. 4. Agregar regla de firewall “multi_wan” a la LAN. Debemos ir a la pestaña firewall>rules>LAN para asignarle a la LAN el grupo de Gateway que definimos anteriormente llamado” multi_wan”.Dando doble click que nos aparece por defecto. · En el menu Advanced features>Gateway agregamos nuestro grupo de Gateway como se muestra. En nuestro caso es el grupo multi_wan. 5. NAT outbound Nat que permite la conversión de las ip´s de origen del tráfico de la LAN por las ips de los enlaces con los ISP´s en el mejor de los casos estas serán públicas. En la interfaz de pfSense nos vamos a Firewall>NAT>outbound y agregamos 2 reglas dando click en el símbolo + y nos aparece la siguiente interfaz.. Lo único que vamos a modificar es en la pestaña interfaces donde vamos a definir la regla del NAT ya sea para la WAN1 o para la WAN2 y en source agregaremos la subred de la LAN que en nuestro caso es 172.16.0.0/24. Damos click en Guardar. Ambas reglas deberían quedar como se muestra a continuación. 6. Reglas de NAT para ser alcanzables desde internet Para comprobar que somos alcanzables se ha montado un servidor web en la LAN que escucha peticiones en el puerto 80 de la pc con ip 172.16.0.1 Firewall > NAT > Portforward , damo click en el simbolo + y modificamos el siguiente menu: Se configurara en la en el menú la interface correspondiente a cada ISP, el protocolo TCP/UDP, e source la red entre el ISP que se define y el router PFSense, en Destination la ip del puerto WAN y Destination Port Range HTTP, en Redirect Target ip la ip donde se encuentra el servidor web en nuestro caso 172.16.0.2 , y en Filter Rule Association Pass. Ambas reglas quedan como sigue: Hasta aquí tenemos: · · · · Balanceo de carga Control de fail-over o caída de un ISP. Reglas de NAT para salir a internet Reglas de NAT para ser alcanzables desde internet. Como extra podemos utilizar el sistema operativo PFSense para realizar: DNS interno nos permite tener un DNS interno que resuelva las consultas mas habituales de forma veloz y al mismo tiempo redireccione hacia los DNS externos todas aquellas consultas que no pueda resolver. · Proxy Para filtrar contenido y algunas paginas por sus url que no queramos que los host en nuestra LAN visiten. · Reglas de firewall para bloquear algunos protocolos y algunas ip`s publicas de algunos sitios web para evitar que con la navegación segura “https” los usuarios se salten el proxy. 1. DNS Interno Con la ayuda de la herramienta dns forwarder que viene ya incluida en pfsense podemos implementar un DNS interno, para ello vamos a Service>DNS forwarder donde nos aparece el siguiente menú: · En la parte de las opciones avanzadas vamos a introducir las paginas que queremos que nuestro DNS interno resuelva de manera instantánea, cabe mencionar que todas aquellas consultas que nuestro dns no pueda solucionar deberán ser redireccionadas a los dns definidos en System>General Setup Damos click en el símbolo + y editamos el menú host overrides donde nos aparecen los campos: · · · · Host para ponerle un nombre a la consulta. Domain donde definimos la consulta que habrá que resolver, por ejemplo “facebook.com. ip aquí se define la ip que devolverá el dns interno cuando se realice una consulta. Guardamos. El menu nos deberia quedar similar a este: De esta forma incluso se pueden resolver algunas consultas dns con la dirección localhost de la pc para“Bloquear”el acceso a algunas páginas mediante dns. 2. Proxy filter y proxy server Con ayuda de ambas herramientas podemos bloquear contenidos e incluso algunas url que sea necesarias. Para ello debemos descargar los paquetes squid y squidguard llendo a System>Packege Seleccionamos ambos paquetes y los descargamos. Despues de esto vamos a Services>proxy filter donde nos encontramos con el siguiente menú: · · Con el proxy filter podremos bloquear paginas por su contenido, para ello habilitamos el servicio y el uso de la black list que no es mas que un archivo que contiene todas las ips que queremos bloquea, en la opción Blacklist URL escribimos la dirección de internet donde se encuentra la blacklist que queremos utilizar, luego vamos a la pestaña BlackList y la descargamos. Ahora nos vamos a la pestaña Common ACL donde encontraremos el contenido de nuestra black list y podemos definir ahí que queremos permitir que se pueda ver y que quisiéramos bloquear. Con esto ya estaríamos bloqueando paginas por su contenido, ya se pornografía, drogas, juegos, redes sociales, y muchísimas cosas mas. Proxy server Vamos ahora a la pestaña Service>proxy server El cual podemos utilizar para bloquear paginas atraves del servidor proxy, esta configuración es sencilla y basta con agregar las url que queramos bloquear en el campo Accesscontrol>blacklist 3. Ahora vamos a utilizar las reglas propias del firewall que ya venimos utilizando hasta ahora, como hemos visto pueden ser usadas para muchas aplicaciones, trataremos de explicar las siguientes: Uso de las reglas de firewall para bloquear protocolos específicos en nuestro caso bloquearemos el protocolo ICMP Fuera de la LAN. Cabe resaltar que el trafico ICMP entre la LAN si se permitirá. En vista de la problemática de que el filtro proxy puede ser saltado utilizando navegación segura https, bloquearemos con reglas de firewall el trafico que vaya hacia ciertas paginas. · Vamos a Firewall>Rules y agregamos una regla nueva dando click en +, primero agregaremos una regla que permita el trafico ICMP entre los host de la LAN y luego otra regla que bloquee todo el trafico ICMP, en vista de que cuando un paquete ingresa al firewall este revisa su tabla de reglas en busca de una que concuerde con el paquete, cuando encuentra dicha regla la ejecuta y hace caso omiso de las siguientes reglas, aquí el orden de las reglas si importa. Ahora agregaremos otra regla que bloquee todo el trafico con destino “Las ips de facebook”en nuestro caso bloquemos todas las ips de facebook del rango de la 173.252.0.0/16 asi inhabilitamos también la navegación segura https. ·
Utilizamos netbeans ide 7.3.1 y tomcat7 Bien primero lo primero, TOMCAT es un demonio especial de la familia de apache que se utiliza para dar soporte a paginas JSP y poder prestar ese servicio, es facil de implementar en linux. Una de las ventajas de tomcat es que se puede configurar junto con apache para atender las peticiones http y jsp respectivamente pero para este howto solo vamos a mostrar la configuracion de tomcat. Desde linux en una consola como root tecleamos: #apt-get install tomcat7 Luego de instalarlo y ver que corra bien colocamos la siguiente direccion en el navegador: localhost:8080 Ya que tomcat escucha por el puerto 8080 si todo va bien tendria que salirnos la pagina de bienvenida de tomcat. Esto creara un directorio en /var/lib/tomcat7 donde se encuentran todas las configuraciones de tomcat7, es importante revisar la version de jdk con la que cuenta nuestro linux con el comando: #java -version Debido a que si tomcat es instalado con una version de java menor o mayor a la version de java con la que se compilan nuestras aplicaciones web JSP nos dara un error. Tomcat utiliza un archivo de tipo .war para cargar la pagina jsp, este archivo debe ser copiado ala siguiente direccion: /var/lib/tomcat7/webapp/ y copiar aquí nuestro archivo .war para generar el .war vamos a utilizar netbeans ide pero estoy seguro de que se puede generar con otros ide's. Este archivo .war simplemente mantiene una estructura que tomcat reconoce. Aplicación JSP con NETBEANS 7.3.1. Bueno para instalar Netbeans en linux basta con descargarlo desde la pagina oficial con soporte para java EE e instalarlo con el comando #sh netbeans....... Luego entramos en el netbeans creamos una aplicación WEB y luego de terminarla compilamos. El archivo .war se guarda en la siguiente direccion: /NetbeansProyects/NuestraAplicacion/dist/NuestraAplicacion.war Ahora copiamos este archivo a la direccion del tomcat de la siguiente forma: #cp /NetbeansProyects/NuestraAplicacion/dist/NuestraAplicacion.war /var/lib/tomcat7/webapp/ Reiniciamos el demonio tomcat7 #/etc/init.d/tomcat7 restart y ahora podemos acceder desde el navegador a nuestra aplicación: localhost:8080/NuestraAplicacion o para ipv6 con la direccion ::1 que representa al localhost [::1]:8080/NuestraAplicacion Recuerda que para que no tengamos problemas netbeans debe compilar la aplicación con la misma version de jdk que tengamos en nuestra maquina al momento de instalar tomcat7.
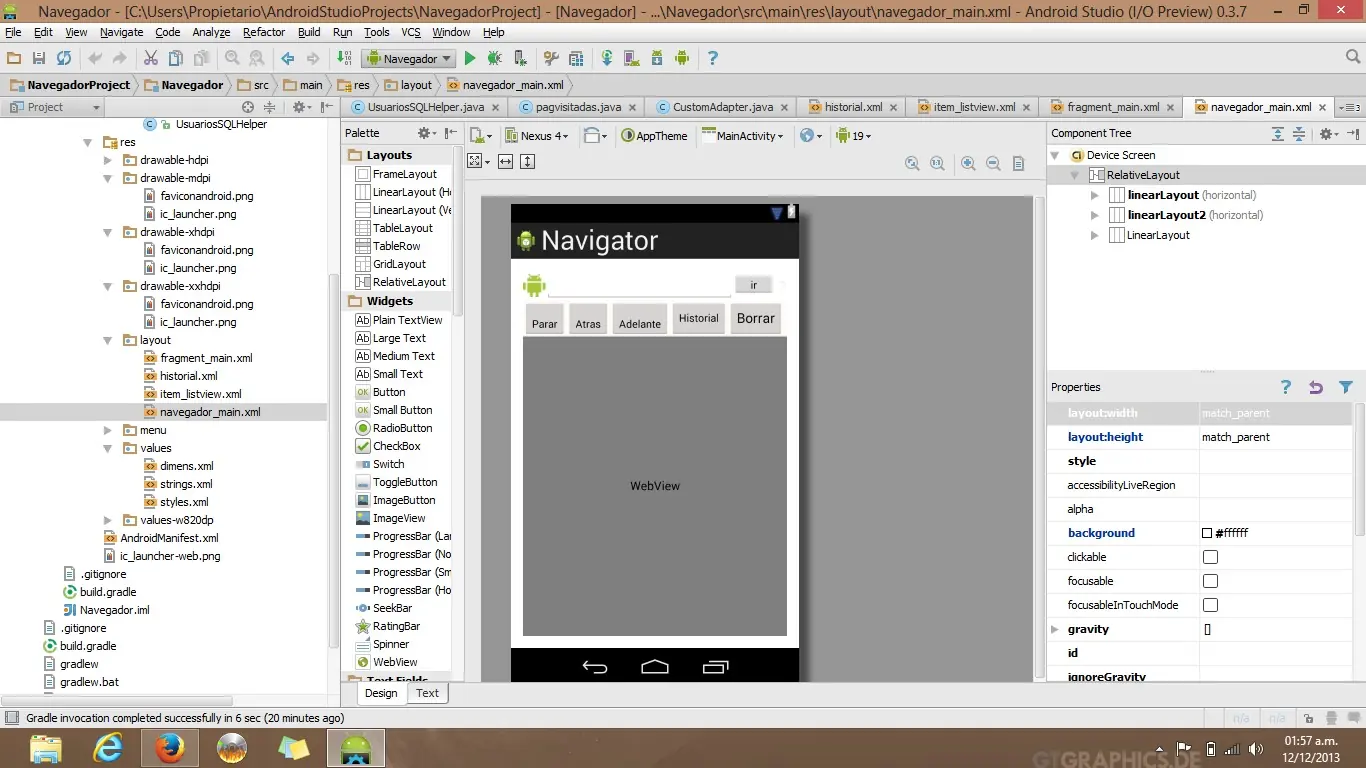
Muy buenas, en este post voy a tratar de explicar mi experiencia en la programacion para dispositivos android, quiero decirles que este post es una forma de poner en practica algunos componentes interezantes de la api de google para desarrollo con el fin de aprender y tratar de facilitar el apredizaje de otros. Utilizare Android Studio aqui una pequeña reseña: http://developer.android.com/sdk/installing/studio.html en su version 0.37... y algo, y es importante que sepan q esta en su version beta y q aun es un poco inestable pero en lo personal me ha funcionado todo de maravilla y una de sus mayores ventajas con respecto a eclipse es q es un entorno de desarrollo unicamente para android. En este post explicare como codificar una especie de navegador web que no se acerca a uno convencional pero que puede servir como partida para aquellos que se dispongan a irse adentrando en esto de la programacion android con la ayuda de un componente android llamado webview que nos permite mostrar contenido HTML ya sea para incrustarlo en nuestras app o para el uso q le daremos en este post, cabe destacar q este componente es la base de apliaciones como ephinari o google chroome entre otros, otra reseña importante es que utilizare una base de datos SQLite para guardar el historial de las paginas que vayamos visitando (Historial completo de dias anteriores) junto con su favicon (Imagen q describe la pagina) fecha y hora de visita a la webpage. Ahora manos a la obra: Paso 1: La interfaz Para el caso de la interfaz les dejo una captura seguido del codigo en xml. Como pueden ver es una interfaz senciilla con 6 botones "Ir, Historial, Atras, Adelante, Parar, Borrar" de los cuales mas adelante explico sus funciones, una caja de texto, el webview y un ImageView donde mostraremos el favicon de cada pagina y una progressbar para mostrar el progreso del proceso de carga de la pagina. Aca el xml: <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" android:paddingLeft="@dimen/activity_horizontal_margin" android:paddingRight="@dimen/activity_horizontal_margin" android:paddingTop="@dimen/activity_vertical_margin" android:paddingBottom="@dimen/activity_vertical_margin" tools:context=".MainActivity" android:background="#ffffff"> <LinearLayout android:orientation="horizontal" android:layout_width="fill_parent" android:layout_height="wrap_content" android:id="@+id/linearLayout" android:layout_alignParentTop="true" android:background="#ffffff" android:layout_alignParentRight="true"> <ImageView android:layout_width="30dp" android:layout_height="fill_parent" android:src="@drawable/faviconandroid" android:id="@+id/imageView"/> <EditText android:layout_width="184dp" android:layout_height="wrap_content" android:id="@+id/editText" android:layout_weight="2.57" android:inputType="text" android:layout_marginRight="-1dp" android:layout_marginTop="3dp" android:textColor="#010101" android:layout_marginLeft="-1dp" /> <Button style=?android:attr/buttonStyleSmall android:layout_width="wrap_content" android:layout_height="30dp" android:text="@string/ir" android:id="@+id/button" android:layout_alignParentRight="true" android:layout_marginLeft="-2dp" android:layout_weight="0.31" /> <ProgressBar style=?android:attr/progressBarStyleSmall android:layout_gravity="center" android:layout_width="wrap_content" android:layout_height="wrap_content" android:id="@+id/progressBar"/> </LinearLayout> <LinearLayout android:orientation="horizontal" android:layout_width="fill_parent" android:layout_height="wrap_content" android:layout_below="@+id/linearLayout" android:id="@+id/linearLayout2" android:background="#fffbf9"> <Button style=?android:attr/buttonStyleSmall android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Parar" android:id="@+id/stop" android:gravity="bottom" android:layout_gravity="bottom" /> <Button style=?android:attr/buttonStyleSmall android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Atras" android:id="@+id/atras" android:layout_gravity="center_horizontal|bottom" android:gravity="bottom" /> <Button style=?android:attr/buttonStyleSmall android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Adelante" android:id="@+id/adelante" android:gravity="bottom" android:layout_gravity="bottom" /> <Button style=?android:attr/buttonStyleSmall android:layout_width="wrap_content" android:layout_height="fill_parent" android:text="Historial" android:id="@+id/history"/> <Button android:layout_width="wrap_content" android:layout_height="fill_parent" android:text="Borrar" android:id="@+id/BorrarHistorial" /> </LinearLayout> <LinearLayout android:layout_width="fill_parent" android:layout_height="fill_parent" android:layout_below="@+id/linearLayout2" android:layout_alignParentBottom="true"> <WebView android:layout_width="fill_parent" android:layout_height="fill_parent" android:id="@+id/webView" android:background="#ffffff" /> </LinearLayout> </RelativeLayout> Paso 2: La clase principal "Navegador_Activity" Bueno el objetivo del post no es explicar en si como se programa en android si no tratar de dejar claras algunas de las funciones mas comunes que utiliza un webview y para q nos pueden servir. Primero setearemos las variables necesarias para utilizar nuestro webview: protected WebView webview; protected WebView webview; protected Button ir; protected Button atras; protected Button adelante; protected Button stop; protected Button History; protected Button Borrar; protected ProgressBar progressBar; protected ImageView fav; Luego asignamos estos "Contenedores" a los componentes de nuestro layout principal: webview = (WebView) findViewById(R.id.webView); fav = (ImageView) findViewById(R.id.imageView); url = (EditText) findViewById(R.id.editText); ir = (Button) findViewById(R.id.button); atras = (Button) findViewById(R.id.atras); adelante = (Button) findViewById(R.id.adelante); Borrar = (Button) findViewById(R.id.BorrarHistorial); stop = (Button)findViewById(R.id.stop); History= (Button) findViewById(R.id.history); progressBar = (ProgressBar) findViewById(R.id.progressBar); Hacemos que nuestra Activity implemente el evento listener para asignarle el onclicklistener a nuestros botones: public class Navegador_Activity extends Activity implements View.OnClickListener Y luego asignamos el evento a nuestros botones de la siguiente forma (hacemos esto para todos los botones): ir.setOnClickListener(this); ok luego de eso seguimos con un poco de funcionalidad: Habilitar soporte para JAVAScript en nuestro webview: Para elllo hacemos uso de las opciones del webview (podran apreciar q son muchas) webview.getSettings().setJavaScriptEnabled(true); Habilitar soporte para hacer zoom sobre las paginas webview.getSettings().setBuiltInZoomControls(true); webview.getSettings().setSupportZoom(true) Habilitar base de datos de favicons Para los que este pensando en ¿Que es un favicon? Es una imagen pequeña que identifica al sitio y se envia junto con la pagina web (Lo usaremos luego). WebIconDatabase.getInstance().open(getDir("icons", MODE_PRIVATE).getPath()); Supuestamente este elemento a sido eliminado en la api 18 pero probando no se reciben los favicons. Agregar pagina de inicio webview.loadUrl("http://www.debian.org"); //PAGINA WEB POR DEFECTO /Repara el bug para poder acceder a los texfields de las paginas web!! Esto permite manejar el evento touch del textview para q nos permita utilizar las cajas de texto y formularios de las paginas que visitemos. webview.setOnTouchListener(new View.OnTouchListener() { @Override public boolean onTouch(View v, MotionEvent event) { switch (event.getAction()) { case MotionEvent.ACTION_DOWN: case MotionEvent.ACTION_UP: if (!v.hasFocus()) { v.requestFocus(); } break; } return false; }}); El boton "Ir" Bueno hasta aqui todo bien, el siguiente paso es sobreescribir el metodo onClick que controla el evento de click sobre los botones de nuestra Actividad. Adentro agregamos una porcion de codigo que va a identificar que boton desencadeno dicho evento para ello agregamos lo siguiente (Fuera del metodo onCreate de nuestra activity) @Override public void onClick(View view) { if (view.getId()==ir.getId()){ try{ String page = url.getText().toString(); webview.loadUrl(page); }catch (Exception e){ //Aqui pueden colocar alguna porcion de codigo para manejar algun eventual error } } Basicamente lo que estamos haciendo es poner una condicionante que determine si se trata del boton ir para luego tomar lo que este en el textbox y luego cargarlo en el webview con ayuda del metodo .loadUrl(string pagina); Ahora vamos a sobreescribir otro par de metodos con ayuda de unas propiedades bien especificas de los webview Estas propiedades nos permitiran complementar las funciones del boton "Ir" WebChromeClient Este es una propiedad que nos va a permitir sobreescribir los metodos onRecivedIcon y onRecivedTitle para manejar el titulo de la pagina y el favicon, esto de la siguiente manera: webview.setWebChromeClient(new WebChromeClient(){ @Override public void onReceivedIcon(WebView view, Bitmap icon){ fav.setImageBitmap(icon); //Aqui recibimos el favicon (en formato bitmap) y lo introducimos en nuestro ImageView } @Override public void onReceivedTitle (WebView view, String title){ getWindow().setTitle("xtiyo on "+title); //Aqui recibimos el titulo de la pagina en String y lo introducimos en el titulo de nuestra Activity } WebViewClient Esta propiedad sirve para sobreescribir metodos que tienen que ver con diferentes momentos de la vida de la pagina web para este caso usaremos solo onPageStarted, onPageFinished y onRecivedError. webview.setWebViewClient(new WebViewClient() { @Override public void onPageStarted (WebView view, String url, Bitmap favicon){ progressBar.setVisibility(View.VISIBLE); //Este metodo se ejecuta cuando una pagina empieza a cargarse, en nuestro caso vamos a //hacer que nuestro progressBar se mantenga visible cuando la pagina empieze a cargar } @Override public void onPageFinished(WebView view, String url){ progressBar.setVisibility(View.INVISIBLE); //Este metodo se ejecuta al finalizar la ejecucion de carga de la pagina, por lo cual aqui //hacemos invisible nuestra progressbar. } @Override public void onReceivedError(WebView view, int errorCode, String description, String failingUrl) { AlertDialog.Builder builder = new AlertDialog.Builder(Navegador_Activity.this); builder.setMessage(description).setPositiveButton("Aceptar", null).setTitle("Error! web page "+failingUrl); builder.show(); //ahora esta porcion de codigo se ejecutara cuando se reciba un error en el proceso de carga //de la pagina. Por lo cual solo mostraremos el error en una ventana emergente. error=1; } } El boton "Atras" y "Adelante" Para explicar esta funcionalidad debo decirles que el webview guarda automaticamente un historial de todas las paginas visitadas, esta informacion es limitada y es util solo durante el tiempo de ejecucion de la aplicacion, lo que quiere decir que al terminar la ejecucion de la aplicacion esta info se pierde. para el caso de nuestro boton el codigo seria el siguiente dentro del evento onClick que ya declaramos agregamos otra condicionante asi: if (view.getId()==atras.getId()){ if(webview.canGoBack()){ webview.goBack(); //Revisamos si existen paginas que visitar. } getWindow().setTitle("No existen paginas que visitar"); } if (view.getId()==adelante.getId()){ if(webview.canGoForward()){ webview.goForward(); } getWindow().setTitle("No existen paginas que visitar"); } El boton "STOP" Este lo utilizo para detener la carga de una pagina y basta con agregar lo siguiente en el evento del boton: if (view.getId()==stop.getId()){ webview.stopLoading(); //Le decimos al webview que detenga el proceso de carga de la pagina } Hasta ahora el navegador debe verse asi: El boton "Historial" Este lo explicare en otro post, pronto colocare un video tutorial y la 2da parte del tuto xq este ya quedo bastante extenso xD. Cualquier duda estamos a la orden.
El siguiente post trata de explicar una de las tantas formas provistas por oracle para realizar una replicacion stream entre 2 bases de datos, cabe resaltar que este tipo de replicacion es la unica forma de realizar un stream en la instalacion standard del oracle 11g r2 citando la mismisima documentacion de oracle (y en letras pequeñas como toda informacion importantisima xD) Bueno ahora un poco de informacion hacerca de la replicacion sincrona, esta es una forma bastante sencilla de replicar tablas que se encuentre en 2 bases de datos diferentes utilizando QUEUES (o colas), esta tambien es una de sus limitantes ya que solo se pueden replicar ciertas tablas otra situacion es que solo se pueden replicar DML con este metodo. Este tipo de replicacion es usada en aplicaciones sencillas en las cuales el flujo de datos a replicar es pequeño (unas pocas tablas), si se quiere replicar todo un esquema o toda una base de datos se recomienta realizar una instalacion enterprise (si se puede) y realizar el stream con un metodo que utilize PROCESOS para realizar el stream. Para mas informacion: http://docs.oracle.com/cd/B28359_01/server.111/b28321/strms_capture.htm#STRMS168 Antes que todo, debemos crear las Bases de Datos en modo archive log. En nuestro caso se creara la base de datos BDA en el servidor #1 y BDB en el servidor #2. Ahora manos a la obra!!! CONFIGURACION DEL ENTORNO DE RED. Ambos servidores se encuentran conectados punto-punto utilizando la subred 172.16.0.0/24. El servidor #1 tiene la dirección 172.16.0.1 y el servidor #2 la dirección 172.16.0.2. Si usted olvido crear la Base de Datos en modo Archive log, puede empezar por el paso 2, de lo contrario vea el paso 3. 1. Agregar las cadenas de conexión respectivas en el archivo TNSNAMES.ORA. El directorio en el que se encuentra el archivo es C:appOracleproduct11.2.0dbhome_1NETWORKADMINtnsnames.ora 1.1 Editar el archivo tnsnames.ora en Servidor #1 (BDA) agregando la siguiente cadena de conexión referente a la Base de Datos BDB. BDB = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.16.0.2)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = BDB) ) ) 1.2 Editar el archivo tnsnames.ora en Servidor #2 (BDB) agregando la siguiente cadena de conexión referente a la Base de Datos BDA. BDA = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.16.0.1)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = BDA) ) ) 2. Habilitar el modo Archive log en ambas Bases de Datos. SQL> shutdown immediate SQL> startup mount; SQL> ALTER DATABASE ARCHIVELOG; SQL> ALTER DATABASE OPEN; SQL> ALTER DATABASE ARCHIVE LOG START 3.Creación de Usuario, tablespace y asignación de privilegios. Estos pasos deben hacer de igual forma en ambas bases de Datos 3.1-Creación de Tablespace y Datafiles. •En su navegador abra el Enterprise Manager y conéctese como usuario sys. •De click en la ficha Servidor, luego diríjase a la sección Almacenamiento y de click a Tablespaces. •Dar click el boton crear; esto abrira una ventana, En la seccion Crear Trablespace coloca el nombre que se le dara al tablespace, en nuestro caso se llama streams_tbs. Ver Imagen 2. •En la seccion Archivo de Datos, dar click en el boton Agregar. Esto abrira la seccion Agregar Archivos de Datos •Escribimos el nombre, el cual sera streams_tbs.dbf. •En la seccion Almacenamiento damos un incremento de 100MB. El tamaño maximo del archivo debe de quedar en Ilimitado. Ver configuracion completa en Imagen 3. •Damos click en Continuar. •Vamos al final de la pagina y damos click en Aceptar Imagen2 Imagen3 Imagen 4 3.2-Crear el usuario strmadmin. •Ir a ficha Servidor. •En el apartado Seguridad damos click en la opción Usuarios. •Se nos abre una ventana en la que hay varios usuarios creados, estos no nos interesan, por lo tanto crearemos uno nuevo, para ello damos click en el botón Crear. •Creamos el usuario strmadmin, con contraseña strmadmin y le asignamos el tablespace creado recientemente streams_tbs y como tablespace Temporal le asignamos el TEMP. Ver Imagen 5. •Damos click en Aceptar y listo hemos creado nuestro usuario. Imagen 5 3.3-Privilegios a otorgarle •Dar click en la ficha Servidor. •Ir a la sección Administración de Enterprise Manager y seleccionamos Usuarios de Enterprise Manager. Nos abrirá una nueva ventana. •En la sección Crear Administrador, agregamos el usuario strmadmin creado recientemente, para ello damos click en la lamparita que se muestra en la Figura 6, se abrirá una ventana en la que debemos seleccionar nuestro usuario strmadmin, damos click en Seleccionar. •Una vez seleccionamos el usuario, damos click en el botón Revisar, luego Terminar. •Ahora lo que queda es dejar nuestro Usuario como Superadministrador, para ello seleccionamos el usuario recién agregado, se abrirá la ventana en la que lo dejamos como Superadministrador como se muestra en la Imagen 7. Damos click en Revisar, luego en Terminar y listo. Imagen 6 Imagen 7 La lista de usuarios debe quedar como se muestra en la Imagen 8. Con esto tenemos a nuestro usuario strmadmin con privilegios de Superadministrador. Imagen 8 3.3.1- Agregacion de Privilegios requeridos con GRANT. Abrimos una consola y nos conectamos como usuarios sys. SQL> grant execute on dbms_aqadm to strmadmin; SQL> grant execute on dbms_capture_adm to strmadmin; SQL> grant execute on dbms_propagation_adm to strmadmin; SQL> grant execute on dbms_streams_adm to strmadmin; SQL> grant execute on dbms_apply_adm to strmadmin; SQL> grant execute on dbms_flashback to strmadmin; SQL> begin dbms_streams_auth.grant_admin_privilege (grantee => 'strmadmin', grant_privileges => true); end; / 3.3.2-Agregar el rol DBA SQL> grant connect, resource, dba to strmadmin; 3.3.3-Agregación de los roles EXP_FULL_DATABASE e IMP_FULL_DATABASE. SQL> grant exp_full_database to strmadmin; SQL> grant imp_full_database to strmadmin; 3.3.4-Agregación de variables de entorno necesarias para el Streams. SQL> alter system set global_names=true; SQL> alter system set Streams_pool_size=100m; 4.Crear el Database link y la conexión de red El dblink debe tener el mismo nombre global de la base de datos de destino, en nuestro caso BDA y BDB; el dblink debe ser creado en el esquema del Database Stream Administrator. Nos conectamos en nuestra Base de Datos y creamos un enlace hacia la Base de Datos a la que nos deseamos conectar. 4.1-Creación de Database Link en Base de Datos de Servidor #1: BDA. Se crea el enlace hacia la Base de Datos de servidor #2 BDB SQL> CONNECT strmadmin/strmadmin@BDA SQL> CREATE DATABASE LINK BDB CONNECT TO strmadmin IDENTIFIED BY strmadmin USING 'BDB'; 4.2- Creación de Database Link en Base de Datos de servidor #2: BDB. Se crea el enlace hacia la Base de Datos de servidor #1 BDA. SQL> CONNECT strmadmin/strmadmin@BDB SQL> CREATE DATABASE LINK BDA CONNECT TO strmadmin IDENTIFIED BY strmadmin USING 'BDA'; 5.Creación de las colas. Este paso debe llevarse a cabo en el Enterprise Manager, ingresando con el usuario que se creó anteriormente y con su respectiva contraseña. Esto debe de realizarse en ambas Bases de Datos. Se crearan 2 parámetros de inicialización, con nombres, capture_queue y apply_queue . Vea el siguiente enlace y diríjase a la sección To set the GLOBAL_NAMES initialization parameter to TRUE at a database: http://docs.oracle.com/cd/B28359_01/server.111/b28324/tdpii_common_ii.htm#CHDJHCAI •Ir a la pestaña Movimiento de Datos •En la sección Streams seleccionar la opción Gestionar Colas Avanzadas. Esto abrirá una nueva ventana •Buscamos un botón que dice Crear. •Seleccionamos Cola Normal, Tipo de Dato SYS.ANYDATA •Creamos las colas capture_queue y apply_queue como se muestran en las Figuras Imagen 9 e Imagen 10. Imagen 9 Imagen 10 6.Creación de tabla en usuario HR. Conectarse al esquema de la Base de Datos en el que se desea crear una nueva tabla. Si no ha desbloqueado el esquema, puede hacer lo siguiente en SQLPLUS desde el usuario sys. Para este caso se usara el esquema hr. SQL> alter user hr account unlock identified by hr; Con esto desbloqueamos el esquema hr y le asignamos la contraseña hr. Nos conectamos a dicho esquema. SQL> connect hr/hr@BDX Donde X representa A o B, Si está en maquina Servidor #1 reemplace BDX por BDA, de lo contrario reemplácela por BDB. Ahora creamos la tabla. SQL> create table alumno ( ID number primary key, nombre varchar2(20), carrera varchar2(20)); 7.Creación y agregación de reglas del apply process en ambas Bases de Datos. 7.1.1-Creación del apply process en BDA ubicada en Servidor #1. BEGIN DBMS_APPLY_ADM.CREATE_APPLY( queue_name => 'strmadmin.apply_queue', apply_name => 'apply_emp_dep', apply_captured => FALSE); END; / 7.1.2- Agregación de reglas del apply process en BDA ubicada en Servidor #1. BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.alumno', streams_type => 'apply', streams_name => 'apply_emp_dep', queue_name => 'strmadmin.apply_queue', source_database => 'BDB'); END; / 7.2.1-Creación del apply process en BDB ubicada en Servidor #2. BEGIN DBMS_APPLY_ADM.CREATE_APPLY( queue_name => 'strmadmin.apply_queue', apply_name => 'apply_emp_dep', apply_captured => FALSE); END; / 7.2.2- Agregación de reglas del apply process en BDB ubicada en Servidor #2. BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.alumno', streams_type => 'apply', streams_name => 'apply_emp_dep', queue_name => 'strmadmin.apply_queue', source_database => 'BDA'); END; / 8.Configuración de la Propagación para la notificación de cambios. 8.1.En Base de Datos BDA. BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.alumno', streams_name => 'send_emp_dep', source_queue_name => 'strmadmin.capture_queue', destination_queue_name => 'strmadmin.apply_queue@BDB', source_database => 'BDA', queue_to_queue => TRUE); END; / 8.2.En Base de Datos BDB. BEGIN DBMS_STREAMS_ADM.ADD_TABLE_PROPAGATION_RULES( table_name => 'hr.alumno', streams_name => 'send_emp_dep', source_queue_name => 'strmadmin.capture_queue', destination_queue_name => 'strmadmin.apply_queue@BDA', source_database => 'BDB', queue_to_queue => TRUE); END; / 9.Configuración de Captura Síncrona. En ambas Bases de Datos hacer lo siguiente. Esto es necesario para capturar lo que se propaga de la otra Base de Datos con la que se está conectado. BEGIN DBMS_STREAMS_ADM.ADD_TABLE_RULES( table_name => 'hr.alumno', streams_type => 'sync_capture', streams_name => 'sync_capture', queue_name => 'strmadmin.capture_queue'); END; / 10.Configuración de instanciación de SCN. 10.1En Base de Datos BDA. DECLARE iscn NUMBER; BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@BDB( source_object_name => 'hr.alumno', source_database_name => 'BDA', instantiation_scn => iscn); END; / 10.2En Base de Datos BDB. DECLARE iscn NUMBER; BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_TABLE_INSTANTIATION_SCN@BDA( source_object_name => 'hr.alumno', source_database_name => 'BDB', instantiation_scn => iscn); END; / 11.Iniciar apply process. Esta configuración se hace en ambas Bases de Datos. BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_emp_dep'); END; / Ahora solo quedaria probar la replicacion En el servidor 1 en el sqlplus nos conectamos como el usuario hr SQL> conn hr/hr@BDA SQL>insert in to alumno values(1,'Pablo','Moran'); SQL>commit; Ahora en el servidor 2 en el sqlplus nos conectamos como el usuario hr SQL>conn hr/hr@BDB SQL>select * from alumno; Ahora nos deberia aparecer el valor pablo moran q acabamos de ingresar , tambien se puede monitorear las colas stream en el Enterprise Manager en la pestaña >Movimiento de datos (data movement) > Gestionar colas avanzadas Eso es todo Para cualquier duda estamos a la orden! saludos desde El Salvador! Dios les bendiga! Pronto subire los links de los videos del turorial en español a youtube y los posteare aqui
Hola, en este post voy a explicar mas o menos como se debe realizar una coneccion a mysql y a msaccess utilizando el driver ODBC (open database conection) desde Visual Basic utilizando Visual Studio 2012 en windows 8, Todo bajo arquitectura de 64 bits. Lo primero que vamos a hacer es instalar mysql para 64 bits junto con el driver ODBC de mysql que podemos descargar desde el siguiente enlace (Descargar el MSI que pesa mas): http://dev.mysql.com/downloads/installer/5.6.html Desde ahi podemos instalar el driver y mysql server para 64 bits ambos. Paso 1: Vamos a configurar un origen de datos obdc con la ayuda de el asistente que lleva el mismo nombre, para ello en win8 vamos al menu y escribimos “ODBC” de la siguiente manera: Paso 2: Configuramos un nuevo origen de datos en la siguiente pantalla: Paso3: Damos click en agregar y escogemos ODBC ANSI driver para MySQL. A este paso es importante revisar que dicha configuracion la estamos realizando para 64 bits. Paso 4: Damos click en finalizar y llenamos los campos con la informacion referente a nuestra coneccion. Paso 5: Hacemos una prueba de la coneccion y damos click en ok, es importante darnos cuenta que el nombre que coloquemos al campo “Data Source Name” es el que nos va a permitir identificar nuestro origen de datos desde VB. Paso 6: De paso configuraremos datasource para Msaccess en la imagen del paso 3 escogemos “Microsoft Access Driver *.mdb,*.accbd” esto nos permitira configurar el nuevo origen de datos y damos click en finalizar. Paso 7: Escogemos la ubicación de nuestra base de datos creada en msAccess y le ponemos un nombre a la coneccion yo le puse msaccess y escogi mi base de datos llamada prueba.accbd y damos click en ok. Paso 8: Verificamos los origenes de datos que tenemos configurados hasta ahora, contamos con una llamada “mysql” y otra llamada “msaccess”. Paso 9: Vamos a Visual Basic y creamos un nuevo proyecto al cual llamare “Practica 9” de tipo windows form y la interfaz nos debera quedar de este modo: Paso 10: LA APLICACION EN VISUAL BASIC Los espacios de nombres usados para realizar la coneccion son los siguientes: Imports System.Data Imports System.Data.Odbc Ahora creamos un objeto de tipo “OdbcConnection” que es el objeto que almacenara la coneccion: Public coneccion As OdbcConnection Dentro del codigo del evento del boton Conectar: MYSQL Private Sub Button1_Click(sender As Object, e As EventArgs) Handles Button1.Click Try coneccion = New OdbcConnection("dsn=mysql")'ponemos el nombre del origen de datos q conf antes coneccion.Open()'abrimos la coneccion Label1.Text = "Coneccion Exitosa a mysql" Button4.Enabled = True Button1.Enabled = False Catch ex As OdbcException Label1.Text = "Error"'En caso de generarse un error lo mostramos MsgBox(ex.Message, MsgBoxStyle.Information) End Try Msaccess Try coneccion = New OdbcConnection("dsn=msaccess")'Recuerden el nombre q le 'pusimos al origen de datos coneccion.Open() Label1.Text = "Coneccion Exitosa a msAccess" Button4.Enabled = True Button1.Enabled = False Catch ex As OdbcException Label1.Text = "Error" MsgBox(ex.Message, MsgBoxStyle.Information) End Try NOTA: Con esto ya estariamos conectandonos a mysql y a msaccess. Los demas botones los explicare en la practica y en el video. link: http://www.youtube.com/watch?v=y7M7oCDNTdo
En esta practica vamos a implentar nuestro primer reporte en netbeans utilizando el pluggin para llamado JASPER REPORT, de la compañía JasperSoft, anteriormente grave un video de como instalar el pluggin para aquellos que quieran instalarlo pueden consultarlo en el siguiente link: link: http://www.youtube.com/watch?v=eaGLX7UlrnA En la descripcion del video estan los archivos que deben descargar. Ahora la primera pregunta: ¿Que es un reporte? Empresarialmente hablando es un informe que tiene como fin llevar a las manos de quien lo consulte informacion clave hacerca de: Ventas, Variaciones del mercado, costos y todos aquellos datos impresindibles para la toma de deciciones generenciales en las empresas. ¿Como crear un reporte con ayuda de netbeans? Paso 1: Nos vamos a netbeans, dentro de nuestra apliacion creamos un paquete y agregamos un reporte. Paso 2. En la siguiente pantalla escogemos un diseño: Paso 3: Escogemos nombre del reporte y ubicación, las dejamos por defecto y luego en la siguiente pantalla agregamos un QUERY SQL que va a servir para llenar nuestro reporte cuando lo necesitemos, para ello escogemos una “DataSource” que no es mas que una conexión a una base de datos y agregamos la query. En este caso yo agrege una datasource que se llama “my” y luego una consulta sql hacia una tabla que tengo en la base de datos “test” llamada “practica5” en la que solo tengo 2 campos. Paso 4 Ahora agrego la consulta: Paso 5 Agregamos los campos que queramos mostrar en el reporte y listo. Ya lo tenemos. Suerte compañeros!
Esta es la opcion que google facilita a los desarrollares de android una opcion q segun ellos mismos los acercara a otros tipos de desarrolladores, la instalacion es bastante senciilla y en lo personal la interfas me gusta mucho y es bastante intuitiba (mucho mas sencilla q eclipse). Bueno para este tuto yo instale Android Studio en Open suse 12.2 pero deberia funcionar para cualquier otra distribucion, cabe resaltar q esta version de la api de google es completamente gratis y essta en su version 0.1 para este momento acaba de salir, tiene bugs y errores (fuente los mismisimos creadores) pero para mi q hacia esto vamos, si ya desarrollaste en eclipse con el plugging para android es bastante familiar igual es otra opcion. Se deberan seguir los siguientes pasos Instalar e utilizar api de google para desarrollo android 1. descargar ANDROID STUDIO para linux http://developer.android.com/sdk/installing/studio.html 2. crear una carpeta (en mi caso lo deje en el raiz) mkdir /androidapi/ 3. mover el .tgz a dicha carpeta y descomprimirlo en esa localidad. 4. instalar el jdk original ya que linux trae un openjdk pero almenos yo no pude iniciar el android studio con ese jdk, lo pueden descargar de aqui http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html en mi caso para 32 bits 5. mover el jdk para una ubicacion algo asi como /usr/lib/ y descomprimir ay. 6. setear la variable $JAVA_HOME al nuevo path de nuestro jdk export set JAVA_HOME=/usr/lib/jdk1.7.0_21 7. luego ir a la carpeta donde descomprimimos el ANDROID STUDIO en mi caso cd /androidapi/ en esta ubicacion se creo una carpeta llamada 'android-studio' dentro de la cual residen todos los binarios y la aplicacion como tal, para arrancar el android studio debemos entrar a esta carpeta y ejecutar el binario studio.sh /androidapi/android-studio/bin/./studio.sh podes agregar esta ruta a tu path para correrlo desde cualquier hubicacion con esto ya esta solo te saldra una ventanita dentro de la aplicacion donde tendras q colocar la ubicacion del jdk si te la pide solo vas a /usr/lib/jdk1.7.0_21 q es basicamente lo q ya hicimos con esto ya tenemos corriendo android studio y podremos crear nuevas aplicaciones, para mas informacion visita http://developer.android.com/sdk/installing/studio.html

Bueno para este tutorial voy a utilizar netbeans para poder crear las clases y la interfaz grafica de dicha aplicacion, el objetivo es conectarnos a una base de datos de oracle y agregar, eliminar y actualizar los campos de dicha tabla, asi mismo realizar consultas de manera transparente para ello tratare de explicar las clases y metodos q seran necesarios para poder realizar con exito la sesion. Bueno para conectarnos a una base de datos ORACLE necesitamos descargarnos el driver directamente desde la pagina de oracle que nos servira para obtener la funcionalidad, yo descarge el ojdbc6.jar es como el tercero en el siguiente link Bueno esta de mas decir q necesitamos crear un proyecto en netbeans Despues de descargarnos el driver lo debemos agregar a la carpeta Libraries de nuestro proyecto click derecho>addjar buscamos el jar y ya esta: Bueno manos a la obra Para simplificar este tutorial encapsularemos toda la funcionalidad en una sola clase llamada 'funcionalidad', la cual explicaremos paso a paso. Como Paso 1 Creamos la conexion a la base de datos : Este paso es importantisimo porque sin esta conexion no podremos establecer una sesion, a continuacion el codigo: Este metodo de tipo funcionalidad llamado conectar es el q se encarga de crear dicha conexion, lo primero es meter todo el codigo dentro de un try and catch para solventar o manejar cualquier error que pueda darse, luego:: public funcionalidad conectar() { try { Class.forName(" oracle .jdbc.OracleDriver"); Este es el nombre del driver jdbc que descargamos antes String BaseDeDatos = "jdbc: oracle :thin:@localhost:1521:bdb"; Esta parte es importante ya que aqui es donde le decimos a java a que base de datos se va a conectar (el nombre), la ip del host al que se va a conectar (aunque puede ser el localhost), el puerto por el que escucha el listener, vamos que si trabajan con oracle saben lo que es un listener y por ultimo el nombre de la database q en mi caso es bdb. conexion = DriverManager.getConnection(BaseDeDatos, "hr","hr"); if (conexion != null) { System.out.println("Conexion exitosa!"); } else { System.out.println("Conexion fallida!"); } } catch (Exception e) { e.printStackTrace(); } return this; } En esta parte le indicamos a oracle que usuario vamos a usar para la conexion, nosotros usaremos el usuario HR con la contraseña HR tambien PASO 2: Ahora seguimos con la funcionalidad que nos permitira escribir en la base de datos (Insertar, Borrar o hacer update) Escribir metodo es un booleano que devuelve true si se realiza con exito la transaccion o false si hay algun error. public boolean escribir(String sql) { Todo dentro de un try and catch como buena practica de programacion y aquie basicamente recivimos un objeto de tipo String que contiene una sentencia sql a la que le daremos formato en la interfaz grafica, luego creamos un objeto de tipo Statement que nos permite escribir borrar o actualizar valores dentro de la base de datos con el hacemos un executeUpdate de nuestra cadena sql y luego un commit, despues cerramos la conexion. Si existe algun error devolvemos una cadena de error.. try { Statement sentencia; sentencia = getConexion().createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); sentencia.executeUpdate(sql); getConexion().commit(); sentencia.close(); } catch (SQLException e) { e.printStackTrace(); System.out.print("ERROR SQL"); return false; } return true; } PASO 3: ahora vamos a crear el metodo consultar, que no hace otra cosa mas que consultar la base de datos Este es un metodo de tipo ResultSet el cual es capas de almacenar consultas sql tipicas con el comando select y siempre recive una sentencia sql y devuelve un objeto de tipo ResultSet que luego se formatea en la interfaz grafica. public ResultSet consultar(String sql) { ResultSet resultado = null; try { Statement sentencia; sentencia = getConexion().createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); resultado = sentencia.executeQuery(sql); } catch (SQLException e) { e.printStackTrace(); return null; } return resultado; } PASO 4 : la interfaz grafica Yo la hice sencilla porque la tabla solo tiene 3 campos y es bastante compresiba La interfaz se puede realizar con el asistente de netbeans (paleta) o se puede realizar a puro codigo lo que mas les guste, y la funcionalidad que encasilla en los metodos que gestionan los eventos para cada boton. Si tienen dudas me comentan, les dejo parte de la interfaz. import java.sql.ResultSet; import java.sql.SQLException; import java.util.logging.Level; import java.util.logging.Logger; import javax.swing.table.DefaultTableModel; /** * * @author xtiyo */ public class Interfaz_grafica extends javax.swing.JFrame { private void jButton1ActionPerformed(java.awt.event.ActionEvent evt) { // TODO add your handling code here: String sql=""; //int id= Integer.parseInt(jTextField1.getText()); String id=jTextField1.getText(); String n=jTextField2.getText(); String c=jTextField3.getText(); if(jComboBox1.getSelectedIndex()==0){ //String sql="INSERT INTO alumnos VALUES (11,'julio','carrera')"; sql ="INSERT INTO alumno VALUES ("+id+",'"+n+"','"+c+"')"; } if(jComboBox1.getSelectedIndex()==1){ sql = "UPDATE alumnos SET nombre='"+jTextField2.getText()+"',carrera='"+jTextField3.getText()+"' where id="+jTextField1.getText(); } if(jComboBox1.getSelectedIndex()==2){ sql = "DELETE FROM alumno WHERE id="+jTextField1.getText(); } funcionalidad f = new funcionalidad(); f.conectar(); boolean k = f.escribir(sql); if(k==true){ jLabel5.setText("Transaccion exitosa!!"); } else { jLabel5.setText("Error en la transaccion"); } } private void jComboBox1ItemStateChanged(java.awt.event.ItemEvent evt) { // TODO add your handling code here: if(jComboBox1.getSelectedIndex() == 0) { jTextField1.setText(""); jTextField1.setEditable(true); jTextField2.setText(""); jTextField2.setEditable(true); jTextField3.setText(""); jTextField3.setEditable(true); } if(jComboBox1.getSelectedIndex() == 1) { jTextField1.setText(""); jTextField1.setEditable(true); jTextField2.setText(""); jTextField2.setEditable(true); jTextField3.setText(""); jTextField3.setEditable(true); } if(jComboBox1.getSelectedIndex() == 2) { jTextField1.setText(""); jTextField1.setEditable(true); jTextField2.setText(""); jTextField2.setEditable(false); jTextField3.setText(""); jTextField3.setEditable(false); } } private void jButton2ActionPerformed(java.awt.event.ActionEvent evt) { // TODO add your handling code here: funcionalidad f = new funcionalidad(); f.conectar(); ResultSet r = f.consultar("select * from alumno"); DefaultTableModel modelo = new DefaultTableModel(); jTable1.setModel(modelo); modelo.addColumn("ID"); modelo.addColumn("NOMBRE"); modelo.addColumn("CARRERA"); try { while(r.next()){ Object [] fila = new Object[3];//Crea un vector //para almacenar los valores del ResultSet for (int i=0;i<3;i++) fila[i] = r.getObject(i+1); // El primer indice en rs es el 1, no el cero, por eso se suma 1. //añado el modelo a la tabla modelo.addRow(fila); fila=null;//limpia los datos de el vector de la memoria } r.close();//cerrar result-set } catch (SQLException ex) { Logger.getLogger(Interfaz_grafica.class.getName()).log(Level.SEVERE, null, ex); } //Cierra el ResultSet } } Y les anexo la clase funcionalidad o almenos como deberia quedar package oracle ; import java.sql.*; /** * * @author xtiyo */ public class funcionalidad { private Connection conexion; public Connection getConexion() { return conexion; } public void setConexion(Connection conexion) { this.conexion = conexion; } public funcionalidad conectar() { try { Class.forName(" oracle .jdbc.OracleDriver"); String BaseDeDatos = "jdbc: oracle :thin:@172.16.3.1:1521:bdb"; conexion = DriverManager.getConnection(BaseDeDatos, "hr","hr"); if (conexion != null) { System.out.println("Conexion exitosa!"); } else { System.out.println("Conexion fallida!"); } } catch (Exception e) { e.printStackTrace(); } return this; } public boolean escribir(String sql) { try { Statement sentencia; sentencia = getConexion().createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); sentencia.executeUpdate(sql); getConexion().commit(); sentencia.close(); } catch (SQLException e) { e.printStackTrace(); System.out.print("ERROR SQL"); return false; } return true; } public ResultSet consultar(String sql) { ResultSet resultado = null; try { Statement sentencia; sentencia = getConexion().createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); resultado = sentencia.executeQuery(sql); } catch (SQLException e) { e.printStackTrace(); return null; } return resultado; } } Para finalizar desde el metodo main de la clase principal de su proyecto mandan a llamar a la interfaz grafica y todo terminado suerte y saludos! Cualquier duda o comentarios estamos a la orden