ZLeHiZ
Usuario (Perú)
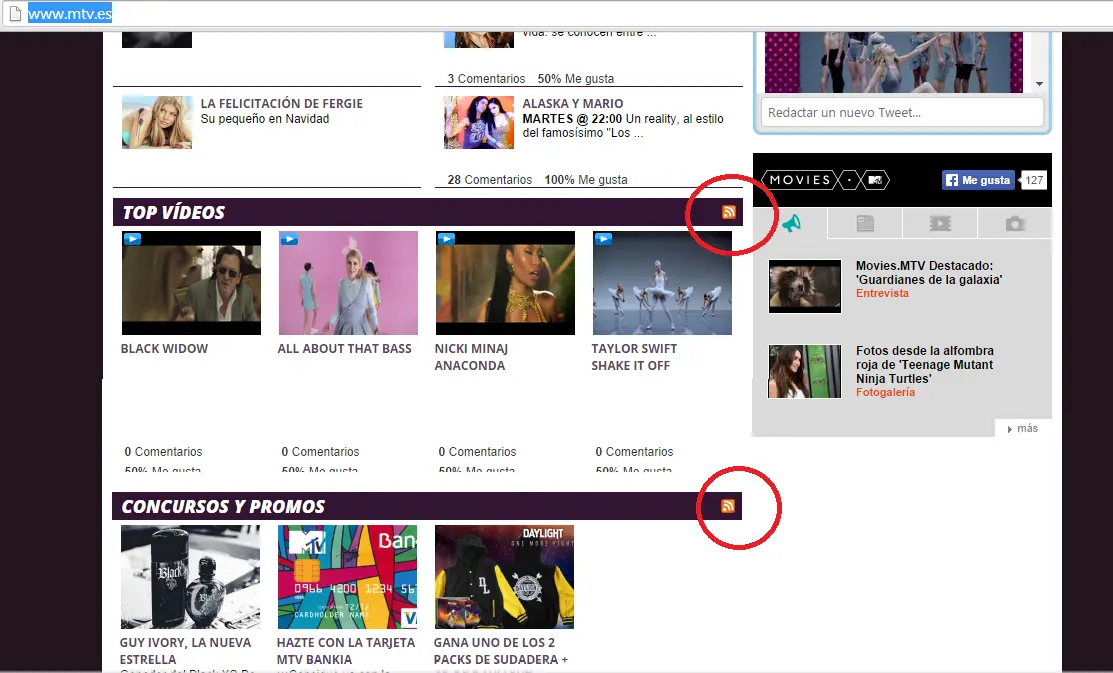
Hola a todos, esta es mi primera vez posteando en Taringa, así que espero que me vaya bien, jajaja, aquí les dejo un pequeño tutorial de como usar los RSS (Really Simple Syndication) para extraer datos de un determinado lugar, esto nos puede servir para muchas cosas, por ejemplo para obtener datos automáticamente y cada vez mas actualizados sin necesidad de hacer un cambio alguno después de su programación. Les dejo un pequeño ejemplo de mi pagina web: http://mystupidmind.com/views/noticias/deport.php Como notarán es una pagina de Noticias , yo posteo a diario esos pequeños fragmentos de noticias para que la pagina este actualizada, simplemente se actualizan cada vez que la fuente de donde saco los datos se actualiza. En otras palabras, yo solo hice la pagina una sola vez, y la pagina se actualiza sola. Deben tener en cuenta que al no actualizar ustedes la pagina, los datos que ustedes obtienen dependen de la fuente, eso quiere decir que si la fuente de donde ustedes sacan los datos se queda sin hacer nada, osea no se actualiza, ustedes no tendrán datos actualizados Bueno, sin mas que decir, vamos al grano: Antes de comenzar, este tutorial esta mas dirigido a las personas que ya saben de programación, a las que se inician en el desarrollo web, y a todos los que estén interesados. Para esto necesitamos alguna fuente de RSS, pueden encontrarlas en algunas paginas, por ejemplo esta vez usaremos : http://www.mtv.es/ Pueden ver que en la pagina de MTV hay unos simbolos, los cuales nos señalan que desde ahi podemos acceder al archivo xml , de donde obtendremos los daros (RSS ). Ahora entramos a esa opción en encontraremos esto: http://www.mtv.es/services/scenic/feeds/get/rss/mgid:hcx:content:mtv.es:88b54b24-3159-4149-aa4e-7fca3a008ed8/ Y para los que no vieron nunca esto, es un archivo en XML , que esta dividido por secciones, en otro post publicaré que es un archivo XML, y como pueden sacar datos, y que otros usos se le dan. Continuemos. Necesitamos copiar el Link de la pagina donde se encuentra el archivo XML . Ahora usando algún lenguaje de programación, en este caso PHP, accederé desde un servidor, para sacar los datos. Aqui dejo el codigo en PHP de la clase RSSreader: Entonces, ahora solo lo uso en mi pagina web: Bueno, les explico de forma rapida como es que se sacan los datos: Si se dieron cuenta en el archivo XML se dividen por secciones, por ejemplo <item> <title> <![CDATA[ Black Widow ]]> </title> <link> <![CDATA[ http://www.mtv.es/musica/artistas/misc/videos/black-widow-1070407/ ]]> </link> <guid isPermaLink="false"> mgid:hcx:content:mtv.es:c16dbddf-d73a-4ed6-bf92-66dc851a515f </guid> <pubDate>lun, 08 sep 2014 02:05:14 EDT</pubDate> <description> <![CDATA[ <img src="http://media.mtvi.com/_!//intlod/MTVInternational/umg_int/gbuv71/400680/GBUV71400680_640x480_1.jpg"> <BR> ]]> </description> <Label> <![CDATA[ Universal Music ]]> </Label> </item> Donde podemos ver que hay datos que podemos sacar, un title, que es un titulo, una descripción , description, y varios datos, que se pueden ver. Eso es lo que extraemos con la clase en PHP , para luego usarla en nuestra pagina web, cogemos todos esos datos y los metemos en un Array, para luego recorrerlo con un FOR, sacando el titulo, link, la fecha (pub_b en el codigo), y descripcion (descrip) , el resultado de todo esto es: Pueden verlo desde mi pagina : http://mystupidmind.com/views/radio/ Ahí el código ya fue agregado a mi pagina web, entonces podemos ver como puede quedar una vez terminado. Espero que me hayan entendido (Obviamente las personas que ya conocen del tema ), y si no conoces aún, espero que te haya interesado, y me gustaría que investiguen acerca de esto, no solo funciona con paginas como MTV, pueden sacarle mucho provecho a todo esto, y usar fuentes de noticias como CNN, MUNDO, o tambien ESPN , o lo que se les antoje. Saludos. PD: Visita mi pagina web, http://mystupidmind.com/ Estaré publicando mas tutoriales, y cosas que les pueda interesar