PasaElLink
Usuario (Argentina)
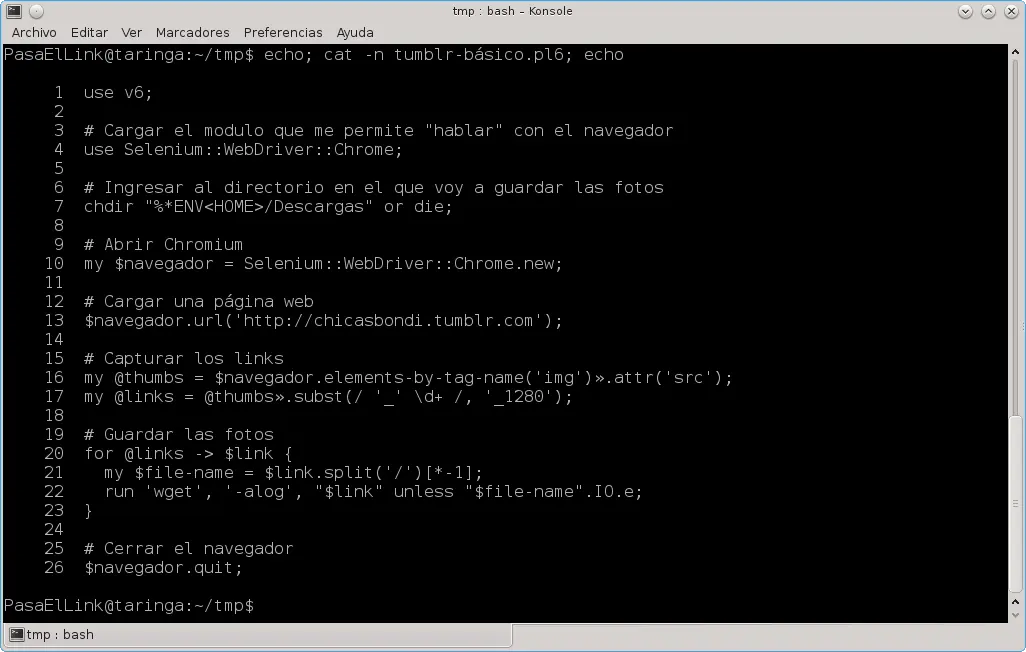
La idea del post es anotar los pasos más básico para descargar contenido desde tumblr usando el navegador. Tiene que ser básico y sin entrar en detalles para permitir que lo puedan implementar en por ejemplo python o cualquier otro lenguaje. En este caso voy a usar perl6, pero python también sirve. En ambos hay que previamente tener instalado selenium. En perl lo pueden instalar desde panda y en python usando pip. En palabras sería: - Cargar un módulo para comunicarse con el navegador (selenium) - Necesitamos un directorio en el cual se va a descargar las fotos - Abrir el navegador - Le pedimos que vaya a una página - Que capture los links - Que guarde las fotos junto con un registro - Y finalmente que cierre el navegador Así como está solo sirve para descargar las fotos del último post que debe tener como diez fotos solamente, para que pueda descargar todas las páginas hay que modificarlo solo un poco, pero de eso ya no ocupo en este post. El código es: Y se ejecuta desde la terminal usando `$ perl6 tumblr-básico.pl6' o se puede comprobar antes de ejecutar con `$ perl6 -c tumblr-básico.pl6' e incluso pedirle que te muestre paso por paso lo que está haciendo con `$ perl6-debug-m' tumblr-básico.pl6'. De ejecutarlo dos o más veces no hay peligro de que pise las fotos ya descargadas, de eso se ocupa la línea 22. En realidad vemos que el script no genera ningún registro sino que es wget quien se ocupa Eso es todo. Espero que les haya gustado y no les sirva, chau.

Con la excusa de de mostrarles como aprovechar el gestor de portapeles (ClipIt), que dicho sea de paso venía instalado y uno se pregunta ¿para qué podré llegar a usar un gestor de portapeles? bueno, muy simple: hagamos que capture enlaces Lo primero que vamos a hacer es configurarlo, para eso vamos a preferencias Las opciones habilitadas en la pestaña 'settings' son esas Ahora ya solo nos queda ir a la pestaña de acciones y empezar a añadir "Acciones" es simplemente un nombre para que podamos identificarlo, puede ir cualquier cosa, lo importante está en "Comando", ahí vamos a escribir lo queremos que pase con el contenido del portapapeles y "%s" va a ser la entrada de nuestro taringa-links.pl. Eso fue todo, espero que les haya servido. Fin del post Sí, ahí termina. Ahora les dejo un ejemplo o mejor dicho el bonus para que lo puedan aprovechar Paso a comentar un poco que hace: primero un breve repaso para el está muy perdido. Una página web es básicamente texto, hay una parte que se ocupa de la estructura (html), otra se ocupa de acomodar visualmente los elementos (css) y finalmente las acciones como que botón se apreta o con que elementos se interactua (javascript). Para el que todavía esté perdido y suene a chino puede visitar y aprender un poco en https://www.w3schools.com/ Ahora bien, dentro de la estructura (html) nuestro pequeño programa va a buscar puntalmente lo siguiente, el resto de la estructura no le importa demasiado <img class="imagen" src="http://..." alt="ola k ase"> ^^^ ^^^^^^ ^^^^^^ línea 21 del script Las primeras diez líneas no sucede mucho, simplemente carga los módulos que vamos a necesitarLínea 12 cambia de directorio porque más adelante vamos a querer guardar un archivoLínea 14 toma el primer argumento de entrada, en nuestro caso el enlace que tan generosamente nos presta el gestor del portapapelesLínea 18 pide la urlLínea 19 muestra el título del postLínea 21 busca las etiquetas img que además sean de la clase imagenLínea 23 abre un archivo al cual vamos a pedirle que añada al finalLínea 24 inicia un bucle del cual le pedimos a la compu que guarde en el archivo que abrimos recién cada atributo srcLínea 27 cierra el archivo Como se usa: Elegimos el postCopiamos desde la barra del navegador con Ctrl+cAhora vamos a abrir el menú de acciones de clipit con Ctrl+Alt+a y a darle a capturar links Y con eso capturamos los enlaces del post y guardamos en un archivo llamado links en nuestra carpeta de descargas, tan simple como eso. En caso de que parezca que no hizo nada se debe a que es probable que el post sea privado y por eso no capture nada. Otra inquietud puede si funciona en taringa cambiandolo un poco también puede funcionar en otras páginas ¿no? la respuesta es depende de si la página usa javascript para generar el contenido porque de hacerlo no capturarías nada, así que antes de que intentes modificarlo para que funcione con instagram u otras ya te voy diciendo que primero te fijes si el contenido está generado con javascript. Una opción en esos casos es automatizar el navegador con Selenium o bien usar PhantomJS simplemente dejo la idea porque se necesitan unas cuantas líneas más de código para que funcione Dejo para que puedan copiar y cambiar a gusto #!/usr/bin/env perl # # taringa-links.pl - Extrae las imágenes dado un post de T! o P! # use strict; use warnings; use autodie; use WWW::Mechanize; use WWW::Mechanize::TreeBuilder; chdir "$ENV{HOME}/Descargas"; my $url = $ARGV[0]; my $mech = WWW::Mechanize->new(); WWW::Mechanize::TreeBuilder->meta->apply($mech); $mech->get($url); print $mech->title(), "\n"; my @imgs = $mech->look_down( _tag => 'img', class => 'imagen' ); open my $fh, '>>', 'links'; for my $img (@imgs) { print $fh $img->attr('src'), "\n"; } close $fh;